

みなさん、こんにちは!タカハシ(@ntakahashi0505)です。
初心者向けエクセルVBAでIEを操作するシリーズです。
前回はこちらの記事で

getElementsByTagNameを使って、特定のHTML要素をタグ名で取得する方法についてお伝えしました。
今回はこれをさらに応用してWEB上の「表」つまり、テーブル要素を取得していきたいと思います。
なにせ、WEBスクレイピングで欲しいのはデータの場合が圧倒的に多いですよね?そしてそのデータは「表」つまりテーブル要素にまとまっている場合が多いわけです。
その方法を知ってしまえば、WEBスクレイピングはかなり制覇したといっても良いのでは?!
ということで早速いってみましょう!
前回のおさらい
前回のプログラムはこちらです。
開いたページのヘッダー要素h1~h3をそれぞれ取得してイミディエイトウィンドウに表示するという内容でした。
Sub MySub()
Dim objIE As InternetExplorer
Set objIE = New InternetExplorer
objIE.Visible = True
objIE.Navigate "https://tonari-it.com/"
Do While objIE.Busy = True Or objIE.readyState < READYSTATE_COMPLETE
DoEvents
Loop
Dim htmlDoc As HTMLDocument
Set htmlDoc = objIE.Document
Dim element As IHTMLElement
Debug.Print "■h1"
For Each element In htmlDoc.getElementsByTagName("h1")
Debug.Print element.innerText
Next element
Debug.Print "■h2"
For Each element In htmlDoc.getElementsByTagName("h2")
Debug.Print element.innerText
Next element
Debug.Print "■h3"
For Each element In htmlDoc.getElementsByTagName("h3")
Debug.Print element.innerText
Next element
End Sub
getElementsByTagNameメソッドでタグ名(h1~h3)を指定することで、該当のHTML要素をコレクションとして取得することができます。
今回は、HTMLでいう表の作り方について確認して、getElementsByTagNameメソッドを使用してテーブル要素をつかんでいきたいと思います。
HTMLのテーブル要素の仕組み
今回は、Yahooファイナンスの時価総額のページにお手伝い頂きます。このページです。
各社の時価総額ランキングを表形式で確認できますが、この表がHTMLではどのように表現されているかを見てみましょう。
Google Chromeで、HTMLの構造を見る場合は Ctrl + Shift + I で開くデベロッパーモードを使うと便利です。
「Elements」というタブでHTMLの階層構造を確認できますが、ここで Ctrl + F でタグなどで要素を検索することができます。
そこで「<table」と検索してみましょう。
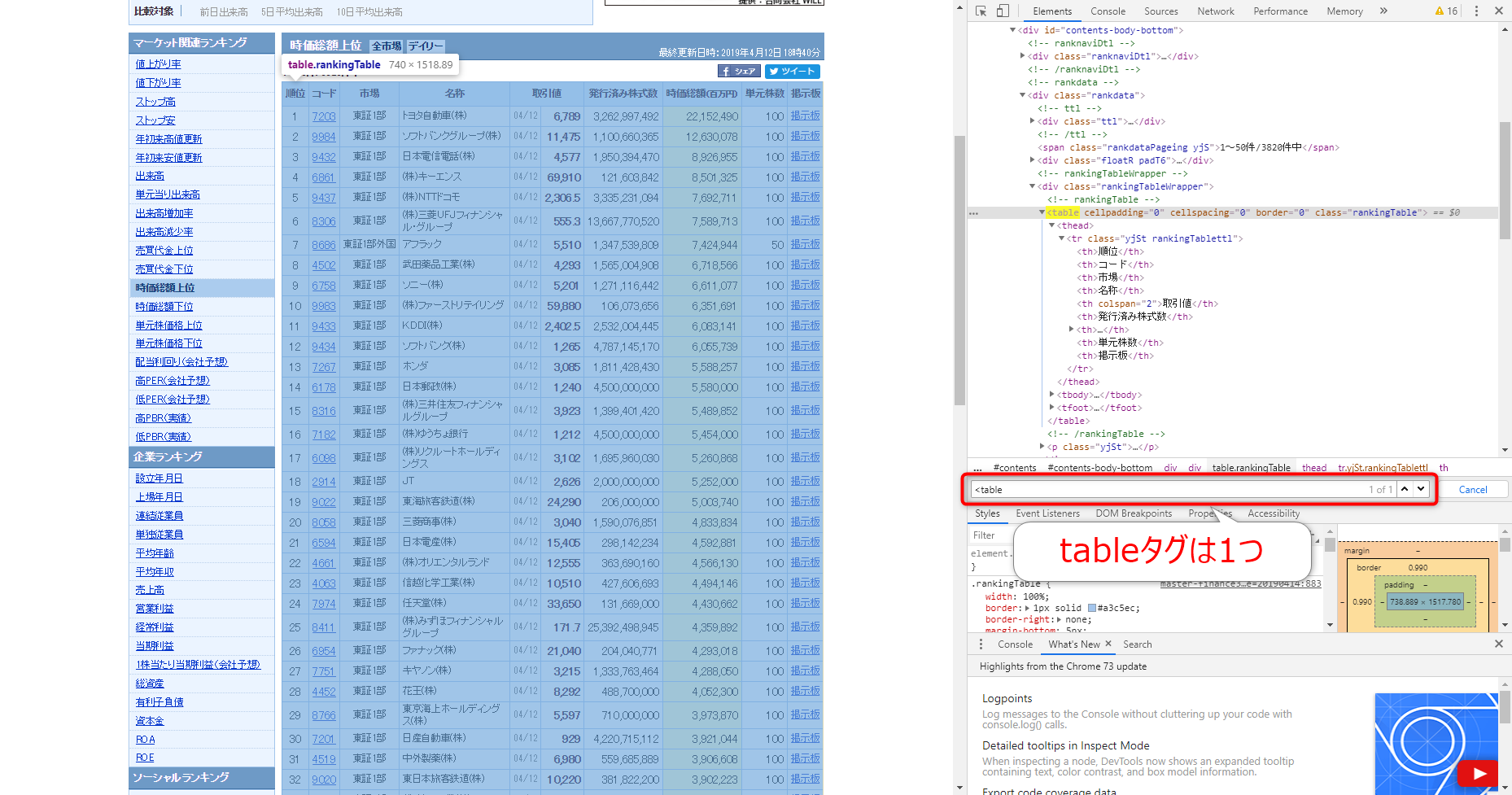
HTMLでの表はテーブルタグ<table>~<table>内に記載をします。
このページにはtableタグは1セットのみなのですが、そのtableタグ内はけっこう色々な要素が含まれています。
まず、tableタグの直下には、thead、tbodyというタグがあることが確認できます。図には入り切らなかったのですが、実はtfootというタグもあります。
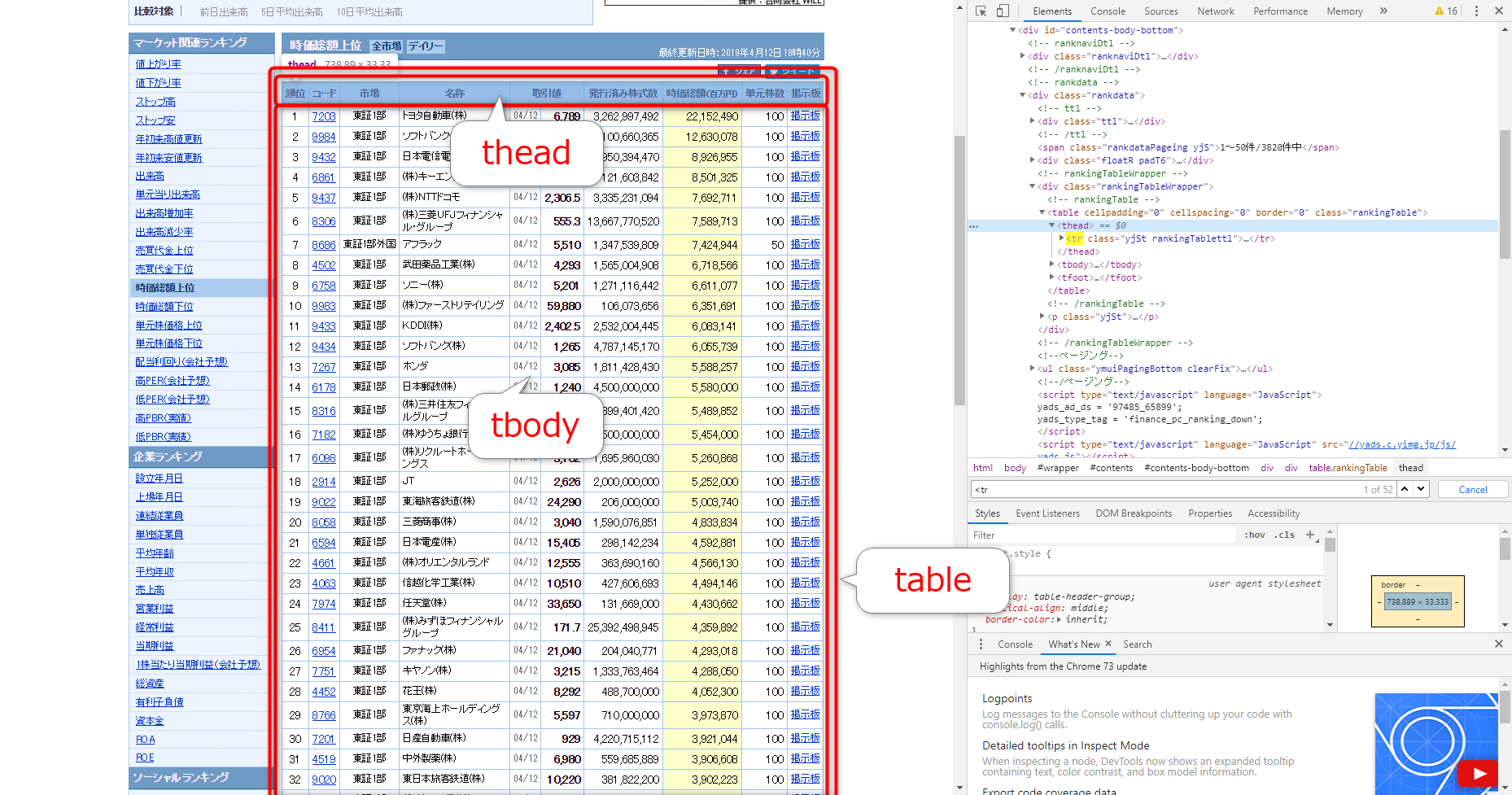
さらに見ていくと、theadの配下にはtr、thというタグが、tbodyの配下にはtr、tdというタグが存在していることがわかりますかね。

つまり、テーブル要素は以下のような階層構造になっているということですね。
| ~ | ~ | …
|---|---|
| ~ | ~ | …
| ~ | ~ | …
それぞれのタグの役割をまとめますと
- table:一つの表を定義する。このタグ内にthead,tbody,tfootといったセクション要素を記述。
- thead:表の見出しセクション。このタグ内に見出しに必要な行数分のtr要素を記述。
- tbody:表の本体セクション。このタグ内に本体として必要な行数分のtr要素を記述。
- tfoot:表のフッターセクション。このタグ内にフッターとして必要な行数分のtr要素を記述。
- tr:表の横一行を定義する。このタグ内に列数分のthやtd要素を記述。Table Rowの略。
- th:表の見出しセルを定義する。このタグ内に見出しのテキストなどを記述。Table Headerの略。
- td:表の値セルを定義する。このタグ内にテキストや数字などを記述。Table Dataの略。
です。WEBスクレイピングする場合はこれらのタグの役割をよーく理解する必要がありますので、バシっと覚えてしまいましょう。
getElementsByTagNameを使ってテーブル内のデータを取得する
これでテーブルの構造は把握できましたので、エクセルVBAでYahooファイナンスのページの本体データつまりtbody要素の中身を取得していきましょう。
タグ名で要素を取得するgetElementsByTagNameメソッドが活躍します。
このページにはtbody要素は1つだけですので、getElementsByTagNameメソッドでtbodyの0番目のインデックスを指定すれば、その要素を取得できますね。
それで、これにより取得できるのは、HTMLTableSectionというオブジェクトになりますが、これに対してさらにgetElementsByTagNameメソッドを使って要素の絞り込みができます。
これで、次の階層にある行を表すHTML要素、つまりtr要素を取得すれば良いですね。
これは、HTMLTableSectionオブジェクトに限らず、HTML要素を表すオブジェクトについては概ね使えますので覚えておくと良いです。
For Each~Nextで取得したtr要素全てについて繰り返す
プログラムの流れとしては、このページ全体のHTMLドキュメントからtbody要素を取得、そしてそのtrタグをコレクションとして取得して、そのコレクション内のtr要素一つ一つについて繰り返す、という流れになります。
ですから、以下のようなFor Each~Nextの繰り返し処理をすれば良さそうですね。
Dim tr As HTMLTableRow
For Each tr In htmlDoc.getElementsByTagName("tbody")(0).getElementsByTagName("tr")
'tr要素に対する処理
Next tr
tr要素の中のテキストを取り出す
tr要素それぞれについて、テキストを取り出してみましょう。
tr要素を表すオブジェクトはHTMLTableRowです。
そのテキストを取り出すにはinnerTextプロパティを使います。
このプロパティも、HTML要素を表すオブジェクトについては概ね使えますよ!
ですから、先ほどのFor Each~Next文の中は以下のようになります。
Dim tr As HTMLTableRow
For Each tr In htmlDoc.getElementsByTagName("tbody")(0).getElementsByTagName("tr")
Debug.Print tr.innerText
Next tr
ランキングの各行のテキストをイミディエイトウィンドウに出力
以上をまとめますと、こんなプログラムになります。
Sub MySub()
Dim objIE As InternetExplorer
Set objIE = New InternetExplorer
objIE.Visible = True
objIE.Navigate "https://info.finance.yahoo.co.jp/ranking/?kd=4"
Do While objIE.Busy = True Or objIE.readyState < READYSTATE_COMPLETE
DoEvents
Loop
Dim htmlDoc As HTMLDocument
Set htmlDoc = objIE.Document
Dim tr As HTMLTableRow
For Each tr In htmlDoc.getElementsByTagName("tbody")(0).getElementsByTagName("tr")
Debug.Print tr.innerText
Next tr
End Sub
これを実行すると

とイミディエイトウィンドウに出力されます。なんか、いい感じに役立ちそうになってきました。
まとめ
HTMLでのテーブルの記述の仕組みについて触れつつ、WEB上のテーブル要素内の行データを取得する方法についてお伝えしてきました。
WEBスクレイピングにおいて、テーブル要素内のデータを取得したいというニーズはかなりありますので、今回のテクニックが役立つ機会も多いものと期待しています。
次回以降、さらに凝った取得の仕方についてお伝えできればと思います。

どうぞお楽しみに!
連載目次:エクセルVBAでIEを操作してWEBスクレイピング
IEを操作してWEBページのデータを取得して、エクセルのデータとして取り込む、つまりWEBスクレイピングをエクセルVBAで実現します。各種WEBページを課題として様々なデータの取得の仕方を解説していきたいと思います。
- 【エクセルVBAでIE操作】10分で終わるセッティングとWEBページの閲覧確認
- 【エクセルVBAでIE操作】HTMLタグと要素そしてドキュメントの取得
- 【エクセルVBAでIE操作】ブラウザの読み込み待ちをしないとダメなのです
- 【エクセルVBAでIE操作】ページ内のリンク先URLを全部取得する
- 【エクセルVBAでIE操作】ディスクリプションなどの要素をname属性でGetする
- 【エクセルVBAでIE操作】hタグなどの要素をタグ名でGetする
- 【エクセルVBAでIE操作】WEBページのテーブル要素を自動で取得する方法
- 【エクセルVBAでIE操作】WEBページのテーブル要素からセルのデータを取り出す方法
- 【エクセルVBAでIE操作】IEで検索窓にキーワードを入力して送信する方法
- 【エクセルVBAでIE操作】検索結果一覧から記事タイトルを取得する方法
- 【エクセルVBAでIE操作】ブログの記事一覧ページから公開日とカテゴリを取得する
- 【エクセルVBAでIE操作】ページャーをめくって複数ページからデータを取得する
- 【エクセルVBAでIE操作】ユーザー名とパスワードを入力してログインをする
- 【エクセルVBAでIE操作】name属性を利用して画像ボタンをクリックする
- 【エクセルVBAでIE操作】alt属性・src属性を利用して画像ボタンをクリックする


コメント
確認なのですが。
新幹線の運行状況をイミディエイトウィンドウに出力
以上をまとめますと、こんなプログラムになります。
~
下の行の表示は正常なのでしょうか?
追伸。
VBAの学習にて参考にさせて頂き、非常に助かっています。
プログラムの箇所の表示が崩れてしまっていましたね…。
ご指摘ありがとうございます。
修正を致しました!
迅速なご対応ありがとうございます m(_ _)m
今後も、VBAの参考にさせて頂きます!!
たいへん わかりやすく 非常に助かっております。
初歩的なことなのですが、エクセルシートに一覧を書き出すことができず、四苦八苦しております。イミディウインドウに出力されたものをどのようにエクセルシートに書き出すか、ご教授くだされば幸いです。
いつもご覧いただきましてありがとうございます。
ご質問の件は、こちらの記事をご参考頂ければと思います。
http://tonari-it.com/excel-vba-invoice/
またその他お知りになりたいことがあった場合は、以下に記事まとめページを作成しておりますので、合わせてご覧いただければ幸いです。
http://tonari-it.com/vba-manual/
今後も弊ブログをどうそよろしくお願いいたします。
Set htmlDoc = objIE.document ‘objIEで読み込まれているHTMLドキュメントをセット
「型が一致しません」と表示されます。
しんかずまさん
コメントありがとうございます。
そのエラーメッセージはその他の通り、変数の型と代入する値(またはSetするオブジェクト)の型が異なっている場合に出ます。
変数htmlDocがHTMLDocument型で宣言されているかご確認いただくのが良いかと思います。
タカハシ様
早速のご回答ありがとうごぜいます。
ブログに掲載されているサンプルプログラムを実行した結果、「型が一致しません」と出ます。宣言も正しいと思います。
自作のプログラムで同じ現象が起きましたので、ぐぐってここに辿り着きました。
1年ほど前は、この書き方でうまく処理できましたが、環境が変わったせいか、うまくいきません。
書籍も参考にしましたが、書籍のサンプルプログラムで「型が一致しません」とでます。
現在の環境は、Win7 ACCESS2013 です。
何かご存知でしたら、ご教授下さい。
しんかずま様
横から誠に失礼します。
VBA初心者のヨコヤマと申します。
私も同じ経験をし、以下の手順で問題発生が消滅したので参考までにお報せします。
なお、私の場合は本連載の “No.4 【エクセルVBAでIE操作】ページ内のリンク先URLを全部取得する”…で「」型が一致しないがでました。
Dim宣言文はタカハシ様のコードをコピペしていて問題が無いと思います。
私ははこの問題が自分特有の環境の性かもと推察していましたが、貴方様にも同様に発生しているみたいですね。
(解決できた手順)
1)VBE画面>ツール>オプション>”□変数の宣言を強制する。” のチェックを外す。(当然、マクロには、Option Explicit 宣言を入れない)
2)15行目の先頭に”‘”を入れて htmlDoc の型宣言文を無視させる。
3)実行すると、”?typename(htmlDoc)で型を調べると?typename(htmlDoc)…>HTMLdocument となり、set文で「型が一致しない」エラーは発生しませんし、当然処理もOKでした。
★自分の推察ですが、Dim文で型の宣言をしない事によりhtmlDocの型が暗黙のうちに Variantにされ、16行目の set文によって、htmlDoc の型が、HTMLDocument にセットされた為ではないでしょうか?
★なお、上記手順1)で、”□変数の宣言を強制する。” のチェックを入れて、2)で 15行目をコメントアウトしたままでも実行時にエラーになりませんでした。この為、このトラブルは自分環境特有の問題ではないかと推察した次第です。
(以上です)