こんにちは!
データアナリストのタダケン(@tadaken3)です。
データ分析やレポート作成をしていて、WEBサイト上にあるデータを使ってみたいって思うことあったりしませんか。5行ぐらいのデータであれば、コピペしてすむかもしれませんが、大量にデータがある場合は、そうもいきません。
もしプログラミングができるのであればスクレイピングという方法を使って、WEBサイトから情報取得することもできます。しかし、スクレイピングは実はプログラマだけの特権ではありません。
Googleスプレッドシートを使えば、標準の関数だけでスクレイピングできてしまうのです。今回は、WEBサイトのデータを簡単に取得する方法をお伝えします。
IMPORTHTML関数を使ってWEBサイトのリストやテーブルの情報取得する
WEB上にあるテーブルやリストからデータを取得するには、Googleスプレッドシートに標準で搭載されているIMPORTHTML関数を使います。
書き方は
です。
クエリには、”table”(表)か”list”(リスト)を指定します。
指数ではWEBサイト上に含まているテーブルもしくはリストのうち、何個目のテーブル・リストを取得するのか指定します。例えば、WEBサイトに3つのテーブルがある場合、2個めのテーブルを取得したい場合は、2を入れます。
IMPORTHTML関数を実践!
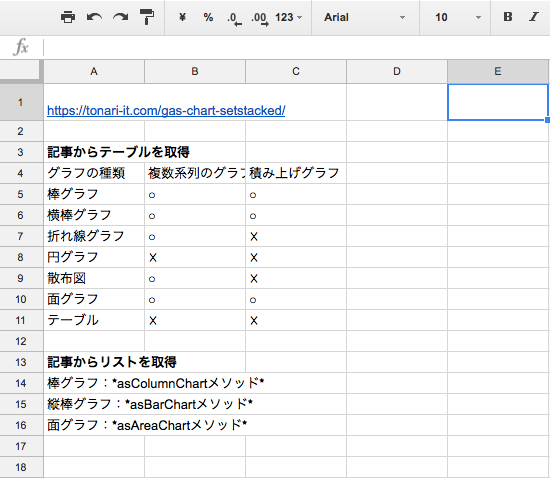
具体的な例を見ていきましょう。今回は「いつも隣にITのお仕事」ブログの以下の記事からテーブルとリストをそれぞれ取得してましょう。Google Apps Scriptで積み上げグラフを作る方法を解説した記事ですね。

まずはテーブルの取得方法です。
リストを取得したい場合は、クエリにリストを指定します。
結果はこのようになります。記事の中にあるテーブルと同じ情報が取得できていたら成功です。
IMPORTXML関数を使ってタグを指定して情報を取得する
WEBサイト上にあるほしいデータが必ずしもテーブルやリスト形式になっているとは限りません。その場合は、IMPORTXML関数を使って、HTMLのタグを指定して情報を取得することができます。
書き方は
です。
タグを指定するのに、XPathという構文を使って指定します。
IMPORTXML関数を実践!
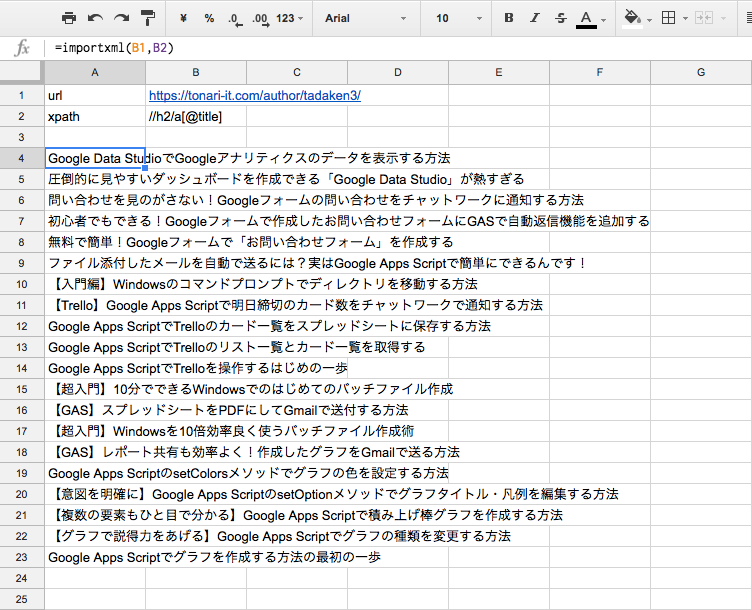
IMPORTXML関数を具体例を使ってご説明しますね。今度の例では、「いつも隣にITのお仕事」の記事一覧ページからタイトル一覧を取得していきます。記事一覧は以下のページです。

実際にタイトル一覧を取得するには以下のように書きます。
“//h2/a/@title”はh2タグの下にあるaタグのtitleを取得するというのを表しています。”/”(スラッシュ)がタグのツリー構造を表していて、@titleで要素を指定しています。
結果はこのようになります。
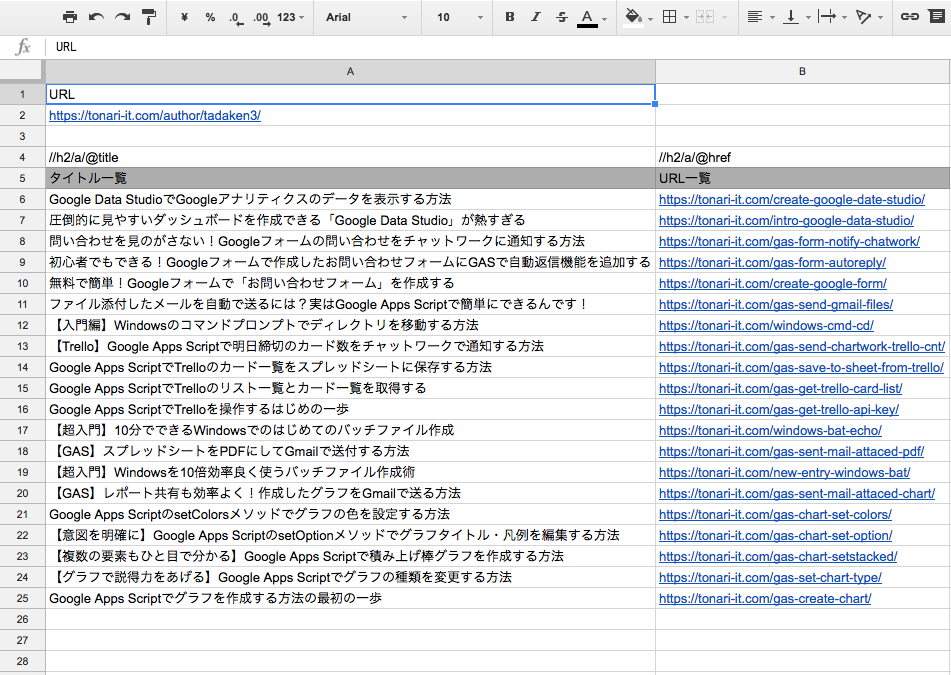
URLを取得したい場合は、”//h2/a/@href”と指定します。例えば、2つを組み合わせて、このような形でタイトルとURL一覧を取得することもできます。
XPathは少しややこしいかもしれませんが、覚えることでHTMLの要素を自在に取得できるようになります。XPathの具体的な記述方法は以下のサイトを参考がなります。少しずつ試してみてくださいな。


まとめ
今回はスプレッドシート標準の関数を使って、WEB上のデータを取得する方法をお伝えしました。
- IMPORTHTML関数でテーブルやリストの情報を取得する
- IMPORTXML関数でHTMLのタグを指定して情報を取得する
これらの関数を使えば、WEB上のデータを簡単に取得することができます。もちろんWEBサイトが更新されれば、スプレッドシートのデータも自動で更新されます。外部データの分析をする際などにご活用ください!次回もデータ分析に関するテクニックをお伝えしていきますね。
どうぞ、お楽しみに!
Twiiterで仕事効率化やプログラミングに関することを情報を発信しています。「いつも隣にITのお仕事」の裏話をお伝えしたり、読者の方と交流したりしています。こちらからTwitterアカウントのフォローをお願い致します。