

みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者かつWindowsユーザー向けにPythonでWebスクレイピングをする方法についてお伝えしています。
前回の記事はコチラ。

Webページを取得した際にエラーかどうかをチェックする方法についてお伝えしました。
これにて安全にWebページのHTMLを取得できるようになりましたので、いよいよ「解析」をして、欲しい情報だけを抽出していくという段取りに入ります。
ということで、今回はPythonでWebページのHTMLを解析するはじめの一歩についてお伝えします。
Beautiful Soupという変な名前のモジュールを使います。
では、行ってみましょう!
前回のおさらい
では、まずは前回のおさらいから。
作成したスクリプトはコチラでした。
import requests
res = requests.get('https://tonari-it.com')
res.raise_for_status()
print(res.text)
- requestsモジュールのget関数で取得したいWebページのResponseオブジェクトを取得
- Responseオブジェクトが正常でなければ例外をスロー
- ResponseオブジェクトからHTML文字列を取り出して表示
という流れです。
今回は、取り出したHTML文字列を解析して、titleタグの情報を取得・表示していきたいと思います。
Beautiful Soupモジュールをインストールする
PythonでHTML解析をするにはBeautiful Soupという変な名前のモジュールが便利です。
HTML文字列から、タグを条件にしたり、id属性を条件にしたりなど、いろいろな方法で要素を取り出すことができます。
では、そのBeautiful Soupという変な名前のモジュールをpipでインストールしましょう。
コマンドプロンプトを開いて、以下コマンド実行です。
pip install beautifulsoup4
すぐにインストールが完了します。
Successfully installed beautifulsoup4-4.6.0
これで準備は完了です。
pipについては以下記事もご覧ください。

PythonでHTML文字列を解析する
では、Beautiful SoupモジュールでHTMLを解析していきましょう。
Beautiful Soupモジュールをインポートする
まず、スクリプトの冒頭でBeautiful Soupモジュールのインポートが必要です。
インストール時には「beautifulsoup4」という名称でしたがが、インポートするときは「bs4」という名称を使いまして
とします。
BeautifulSoupオブジェクトを生成する
Beautiful Soupモジュールを使ってHTMLを解析するためには、まずHTML文字列からBeautifulSoupオブジェクトを生成します。
書式は以下の通りです。
パーサーというのはパースをするやつ、つまり解析をするための機能のことで、ここで好みのパーサーを指定できます。
html5libやlxmlなど、いくつか種類がありますが、使用する場合は別のモジュールのインポートが必要になります。ひとまず、困ることが出てくるまでは、Pythonに標準で付属している「html.parser」を指定しておきます。
さて、こうしてHTML文字列からBeautifulSoupオブジェクトの状態になったら、解析がじゃんじゃんできるよということですね。
title要素を取得する
続いて、BeautifulSoupオブジェクトからtitle要素を取得してみたいと思います。
title要素は、名前の通り、そのページのタイトルをつかさどる要素です。SEOで言うととっても重要です。
BeautifulSoupオブジェクトから特定の要素を取得するには、以下のようにします。
title要素を取得したければ、タグ名を「title」とすれば良いということですね。
なんとシンプル!
では、これまでの一連の命令を使用して、以下スクリプトを作成しましたので実行してみましょう。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
print(soup.title)
実行結果はコチラ。
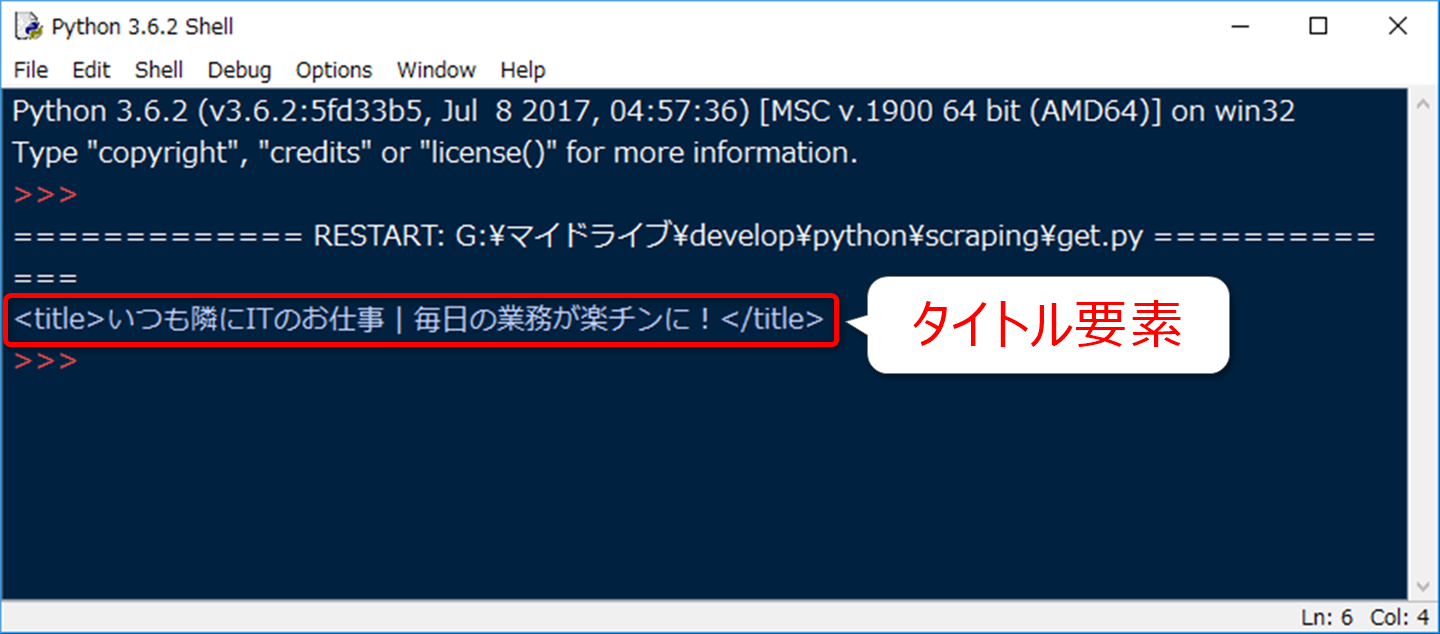
いつも隣にITのお仕事 | 毎日の業務が楽チンに!
バッチリです。
タグで最初の要素を取得する
ですが、一点注意です。
例えば、調子に乗って、h2タグを取得しようとします。
h2タグはいわゆる2番目に大きい「見出し」を表す要素です。で、この要素はページ内にたくさん存在する可能性があり、実際今回のページでも21個あるはずですが、以下スクリプトを実行しても
import requests, bs4
res = requests.get('https://tonari-it.com';)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
print(soup.h2)
得られるのは以下のh2要素だけです。
つまり、「BeautifulSoupオブジェクト.タグ名」で取得できるのは、最初に登場した該当のタグだけです。
ページ内の複数のタグを取得するには別の方法を使う必要があります。
これについては次回の記事でお伝えしていきます。
まとめ
Pythonで取得したWebページのHTMLを解析する初めの一歩についてお伝えしました。
- Beautiful Soupモジュールとそのインストール・インポート
- BeautifulSoupオブジェクトの生成
- BeautifulSoupオブジェクトから特定のタグの最初の要素を取得
などです。今回はtitle要素を取得しただけですが、おそらくこれから色々な解析をしていくことでしょう。
次回は、予告通り、ページ内で複数のタグ要素を取得する方法についてお伝えします。

どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。