
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者かつWindowsユーザー向けということで、PythonによるWebスクレイピングの方法についてお伝えしています。
前回の記事はコチラ。

WebページのHTMLからid属性を条件として要素を取得する方法についてお伝えしました。
これにて
- タグ
- class属性
- id属性
という3つの種類で要素を絞り込むことができたわけで、これらの組み合わせだけでも、色々なパターンのHTML解析ができるのですが、欲しいのは要素ではなくて、テキストだったり、href属性(つまりURL)だったりしますよね。
ということで、今回はPythonを使って特定のHTML要素からテキストと属性データを取得する方法についてお伝えします。
では行ってみましょう。
前回のおさらい
では、まず前回のおさらいから。
作成したスクリプトはコチラです。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('#list h2')
for elem in elems:
print(elem)
当ブログのトップページの記事一覧から記事タイトルを含む要素を取得するものです。
Beautiful Soupオブジェクトのselectメソッドを使って「list」というid名を持つ要素配下からh2タグの要素をつかむことで目的を達成しています。
今回は、さらにその取得した要素群からテキスト(つまり記事タイトル)とそのリンクURLを取得していきたいと思います。
HTML要素からテキストを取得する
Beautiful Soupオブジェクトのselectメソッドで取得できるのはHTML要素を表すTagオブジェクトのリストです。
ですから、そのTagオブジェクトひとつひとつから、テキストを抜き出せば良いということになります。
getTextメソッドでTagオブジェクトからテキストを取得する
Tagオブジェクトから、それに含まれるテキストを取得するには、getTextメソッドを使います。
今回の例でいうと、selectメソッドで取得したTagオブジェクトの例としては
<h2>
<a href="https://tonari-it.com/excel-vba-row-column/" class="entry-title entry-title-link" title="【エクセルVBA】表の最終行・最終列を取得する方法のまとめ">【エクセルVBA】表の最終行・最終列を取得する方法のまとめ</a>
</h2>
となっています。h2タグの中のaタグの中に「【エクセルVBA】表の最終行・最終列を取得する方法のまとめ」が含まれていますが、h2タグに対してgetTextメソッドを使ってあげてもちゃんと目的のブツが抽出できます。
記事タイトルを出力するスクリプト
ですから、冒頭のスクリプトの7行目だけ修正して、以下のようなスクリプトにすればよさそうですよ。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('#list h2')
for elem in elems:
print(elem.getText())
実行をすると、以下のように記事タイトルだけを表示することができます。
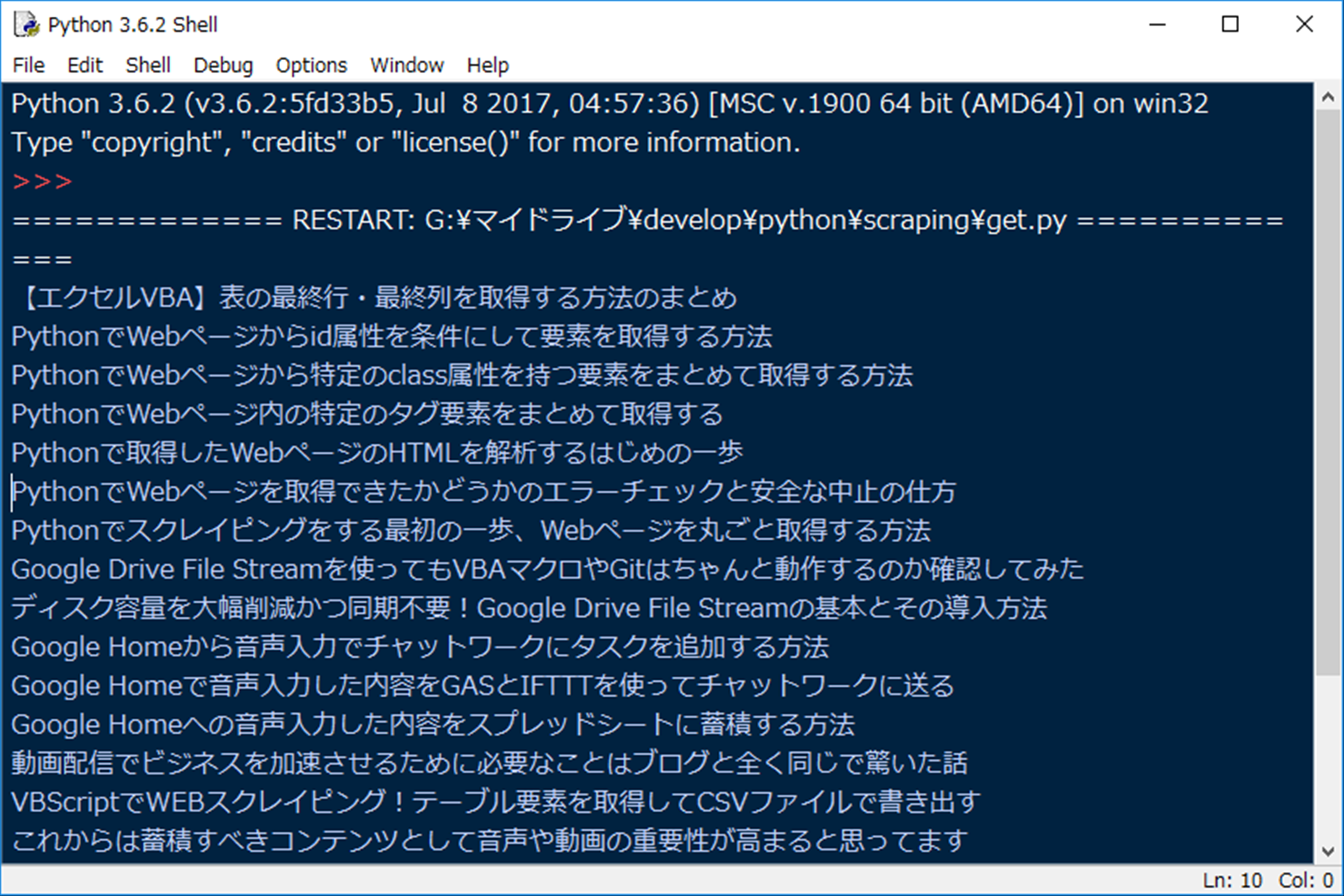
HTML要素から属性の値を取得する
では、続いて各記事のリンクURLを取得してみましょうか。
前述のTagオブジェクトの様子を観察すると、リンクURLは配下のaタグの中の「href=」という属性の値になっています。これはhref属性といいまして、リンクを表すaタグ(アンカータグ)のリンク参照先(Hypertext Reference)を示します。
getメソッドでTagオブジェクトから属性値を取り出す
Beautiful Soupモジュールには、Tagオブジェクトからその要素の指定の属性値を取得するgetメソッドがあります。
書き方はこうです。
ですから、href属性が欲しいのであれば
とすればOKです。
記事タイトルとリンクURLを出力するスクリプト
これを踏まえて各タイトルとそのURLを出力するスクリプトを作ってみましょう。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('#list h2 a')
for elem in elems:
print('{} ({})'.format(elem.getText(), elem.get('href')))
7行目にgetメソッドを使っています。
また、5行目も少し変えています。今回の場合、h2要素はhref属性がありませんので、h2要素の配下のaタグをselectして、それに対してgetメソッドを使うようにしています。
実行結果はコチラ。
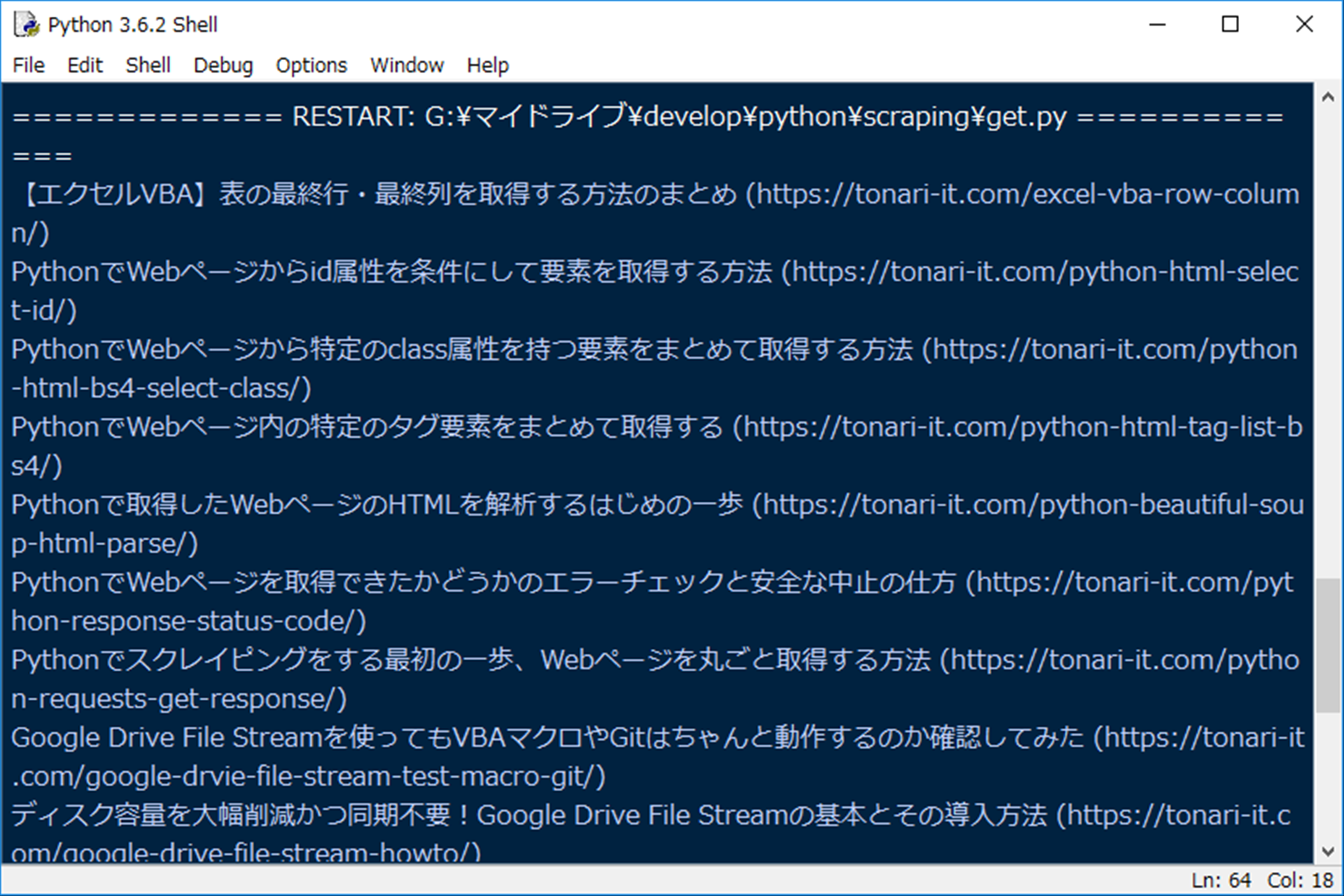
無事に取得できました。
まとめ
PythonでHTML要素からテキストと属性値を取得する方法についてお伝えしました。
- TagオブジェクトのgetTextメソッドでテキストを取得する
- Tagオブジェクトのgetメソッドで属性の値を取得する
引き続き、Webスクレイピングに関するテクニックをお伝えしますね。
どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。


コメント
初めまして
Webスクレイピングに興味を持ち、まずどの言語で作成してみようかと調べているときにこちらのブログにたどり着きました
Pythonのインストール、IDLEの使い方からはじまり、こちらの1~7記事目まで非常にわかりやすく、そして実際にコーディングをしながら楽しく拝見させて頂きました
たった1時間ほどでWebページの取得解析まで最低限のことを理解することができとても感謝しております
これからも素敵な記事の更新楽しみにしております
本当にありがとうございました
通りすがりさん
ありがとうございます!
Pythonの記事も更新していかなきゃですね…!
頑張りますので、引き続きよろしくお願いいたします!!
pythonの記事を拝見させていただいてます。
初めてのプログラミング言語ですが、わかりやすい説明で「できた!」を感じながら勉強しています。
質問なのですが、1つのwebから複数のリンク先を全てスクレイピングするにはどうすれば良いですか。
知識不足で拙い文章で申し訳ありませんが、よろしくお願いします。
アナログ人様
コメントありがとうございます。
いただいた内容は、他の方にもニーズのある情報だと思うので、別記事にて紹介することを検討したいと思います。
ただ、必ず公開するとお約束することはできませんので、その点ご了承いただければありがたいです。