
photo credit: woodleywonderworks middle school math class via photopin (license)
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者かつWindowsユーザー向けにPythonでWebスクレイピングをする方法をお伝えしております。
前回の記事はコチラです。

Webページ内の特定のタグをまとめて取得する方法をお伝えしました。
今回は、別の要素の抽出の方法として、class属性による方法をお伝えします。
では、PythonでWebページから特定のクラスを持つ要素をまとめて取得する方法です。
では、行ってみましょう。
前回のおさらいとお題
まずは、前回のおさらいから。
作成したスクリプトはこちらです。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('h2')
for elem in elems:
print(elem)
当ブログのトップページについて、reauestsモジュールを使ってHTMLをGETして、Beautiful Soupモジュールを使って、その中から「記事タイトル」を取得するために、h2タグの要素をリストで取得して表示するというものです。
それで、実行すると以下のようにShellウィンドウに表示がされます。
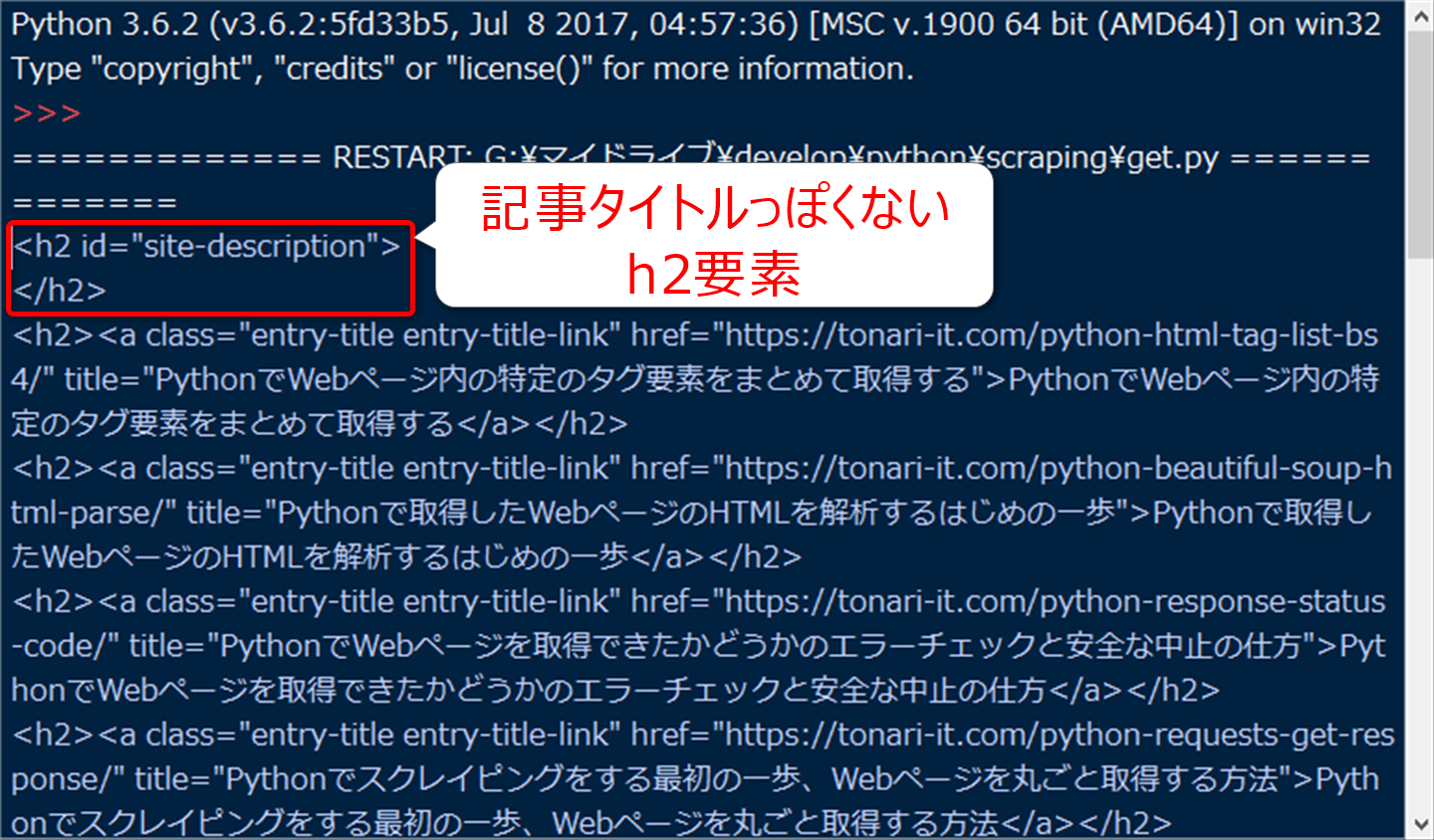
一応、h2タグを取得するという目的は達成しているのですが、一番最初に記事タイトルっぽくない要素がありますね。
Chromeでデベロッパーツールで調べてみると、以下の通り、サイトタイトルの直後にh2タグが使われています。

今回は、この記事タイトルではないh2要素を除外して、記事タイトルを表すh2要素を取得する方法を模索していきます。
特定のclass属性を持つ要素を取得する
作戦を練るためにデベロッパーツールを眺めます。
すると、記事タイトルを表す要素は
- h2タグの中にaタグが含まれている
- aタグに「class=”entry-title entry-title-link”」という文字列が含まれている
という法則があるということに気が付きます。
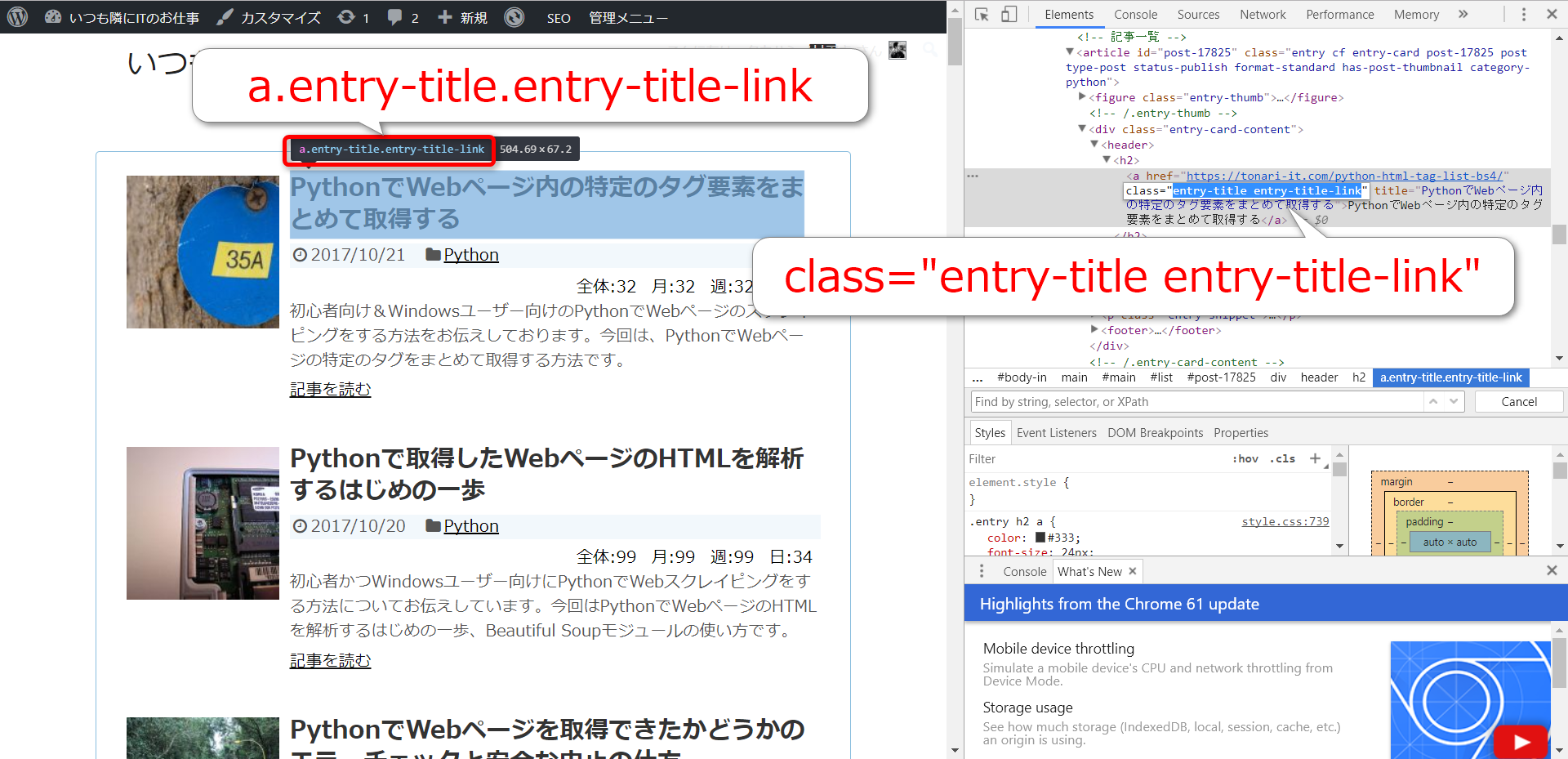
aタグのouterHTMLを抜き出すと以下の通りです。
PythonでWebページ内の特定のタグ要素をまとめて取得する
class属性とは
この「class=」から始まるパラメータは、class属性といい、属性に与える値をクラス名といいます。
定義としては以下引用をご覧ください。
class属性は、その要素にクラス名を指定します。クラス名を指定する主な目的はスタイリングの際の目印であるCSSのセレクタとして使われます。id属性と異なり、ひとつの文書内に同じクラス名を何度でも用いることができます(重複可)。また、半角スペースで区切って列記することで、ひとつの class属性の値に複数のクラス名をつけて複数のスタイルを適用することもできます。
class属性を条件に要素を取得する
BeautifulSoupオブジェクトのselectメソッドは、以下のようにセレクタを引数として渡します。
特定のクラスを持つ要素を取得するセレクタは
というように、ピリオドに続けてクラスを記述します。
それで、今回は「class=”entry-title entry-title-link”」とあるように、「entry-title」と「entry-title-link」という二つのクラス名をclass属性として持っています。
従って、二つのクラス名を持つ要素を取得したいのですね。
二つのクラス名を持つ要素を取得する場合のセレクタは
と連結して記述します。
これで、複数のクラス名を持つということを条件とすることができます。
特定のclass属性を持つ要素を抽出するスクリプト
これを踏まえて、以下のようにスクリプトを変更しました。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('.entry-title.entry-title-link')
for elem in elems:
print(elem)
実行をすると、以下のように指定したクラス名「entry-title」「entry-title-lin」の両方を持つ要素のみ抽出することができました。

まとめ
PythonでWebページから特定のクラス名を持つ要素をまとめて取得する方法についてお伝えしました。
- class属性とは何か
- 特定のクラス名を持つ要素についてのセレクタの書式
さて、次回も別の条件、「id名」で要素を取得する方法についてお伝えします。

どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。