photo credit: The Life of Bryan IMG_3780.jpg via photopin (license)
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
Windowsユーザーかつプログラミング初心者向けに、便利ツールを作りながらPythonを勉強していくという趣旨で記事を書いております。
さて、Pythonは本当にいろいろな方面で活躍するポテンシャルがあるプログラミング言語なのですが、書店など行くとよく「Webスクレイピング」というキーワードが目に入ると思います。
スクレイピングとはすなわち、Webサイトから情報を集めてくる技術のことです。
決まりきっているものであれば、わざわざ人の手で情報を集めてこなくても、プログラムに任せちゃえばラクチンできますもんね。
そして、Pythonはスクレイピングが得意というわけです。
ということで、今回からWebスクレイピングをテーマに便利ツールを作るという内容で連載をしていきたいと思います。
初回の今回は、Pythonでスクレイピングをする最初の一歩、Webページを丸ごと取得する方法です。
では、行ってみましょう!
requestsモジュールをインストールする
まず、Webページを取得する際には、requestsというモジュールを使うと簡単にできます。
これは、標準のPythonに含まれていませんので、個別にインストールする必要があります。
ということで、コマンドプロンプトで以下pipコマンドを使ってインストールをします。
pip install requests

Successfully installed ~ requests-2.18.4 ~
まあ、他にもいろいろインストールされてしますが、requestsモジュールのインストールも無事に完了しているようです。
pipについて詳しい解説は以下の記事をご参考ください。

PythonでWebページを取得する
では、これで準備はバッチリですので、PythonでWebページを取得してみましょう。
requestsモジュールのインポート
まず、先ほどインストールしたrequestsモジュールを使いますので、スクリプトの冒頭でインポートをする必要があります。
これでOKです。
get関数でGETリクエスト
さて、Webページを取得するというのは、厳密に言うと
- 取得したいWebページが置いてあるサーバーに「Webページの情報をちょうだいな」とリクエストをする
- サーバーからのレスポンスを受け取る
という作業になります。
その際のリクエストの種類をHTTPメソッドと言いまして、「GET」とか「POST」とか、いくつかの種類があります。
基本的にWebページのデータが欲しいときはGETを使います。
PythonでGETリクエストをするのが、requests.get関数ということになります。
書き方はこうです。
前置き説明が長かったですが、簡単ですね。
ResponseオブジェクトからWebページの情報を取り出す
requests.get関数の戻り値として、Responseオブジェクトというものが取得できます。
Responseオブジェクトは、以下のような属性を持っていて、つまりサーバーからのレスポンスを表すオブジェクトです。
- text属性:WebページのHTMLデータ
- status_code属性:レスポンスのステータスコード
WebページというのはHTMLというテキストデータで作られていまして、Responseオブジェクトのtext属性として格納されています。
これを取り出せばよいということになりますが、こう書きます。
Webページを取得するスクリプト
以上を踏まえて、スクリプトを用意しました。
import requests
res = requests.get('https://tonari-it.com')
print(res.text)
実行しますと以下のように超大量にHTMLテキストが出力されます。

一応、WebページのHTMLデータが取得できていることは確認できましたね。
htmlファイルとして保存してみる
ただ、ワーって表示しただけなので、これじゃ使いようがありませんね。
ということで、htmlファイルとして保存をしてみます。
htmlファイルと言っても、拡張子がhtmlなだけのテキストファイルですので、以下の記事に書いてあるような内容が使えます。

これを元に作ったのが、こちらのスクリプト。
import requests
res = requests.get('https://tonari-it.com';)
#print(res.text)
with open('tonari-it.html', 'w') as file:
file.write(res.text)
実行すると、「tonari-it.html」というファイルがPythonのファイルと同じフォルダに保存されます。中身を確認してみましょう。
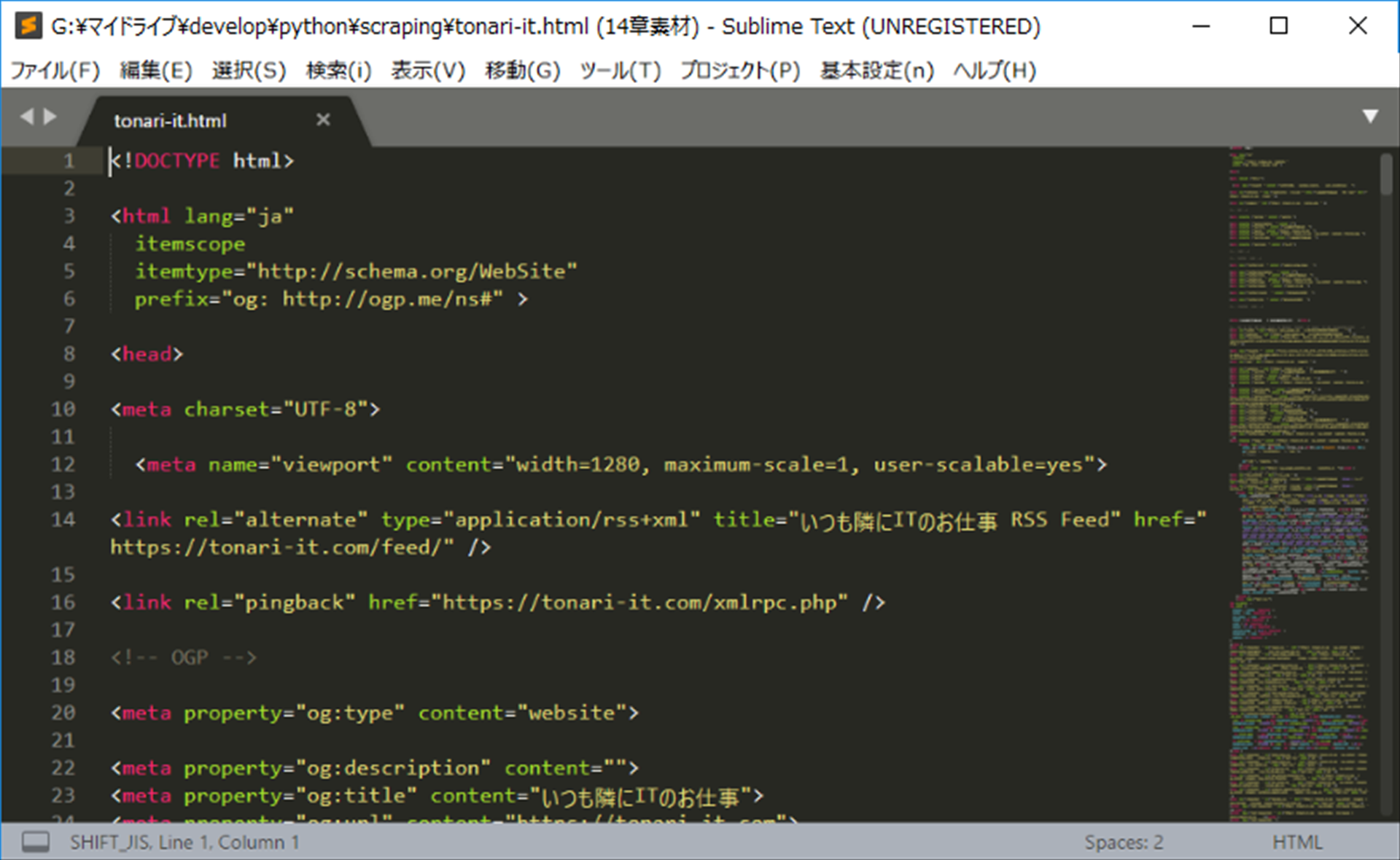
大丈夫そうです。
まとめ
以上、PythonでWebスクレイピングをする第一歩、Webページをまるごと取得する方法についてお伝えしました。
- requestsモジュールのインストールとインポート
- get関数の使い方
- Responseオブジェクトとtext属性の取得
結果、たったの3行のスクリプトで取得できちゃうという…簡単ですね。
次回は、Webページの取得がうまくいかなかった場合にどうするか?ということについてお伝えします。

なお、requestsモジュールのpost関数の使用例として、以下記事もありますので、合わせてご覧ください。

では、次回をお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。