
photo credit: marcoverch Betreten verboten! Zeichen auf einer schlammigen Straße in Brasilien via photopin (license)
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
プログラミング初心者&Windowsユーザー向けにPythonでWebスクレイピングをする方法についてお伝えしています。
前回の記事はコチラ。

最初の一歩ということで、特定のWebページのHTMLを丸ごと取得する方法についてお伝えしました。
では、さっそくHTMLの解析だ!欲しいデータの抽出だ!!
と行きたいところなのですが、ちょっと待ってください。
ほら、スクレイピングって、サーバー調子悪かったり、URL間違えてたりすると取得できないんです。
そんなときどうなっちゃうんですかね?
ということで、PythonでHTTPリクエストする際のエラーのチェックと安全な中止の仕方についてお伝えします。
前回のおさらいと今回のお題
前回作成したスクリプトはコチラ。
import requests
res = requests.get('https://tonari-it.com';)
print(res.text)
requestsモジュールを使って、指定したURLにGETリクエストをして、そのWebページのHTMLを取得して表示、というスクリプトでした。
簡単ですね。
通信ができないときに実行してみる
ただ…Webスクレイピングはスクリプトが正しければちゃんと動くというわけではありません。
- 接続先のサーバーが調子悪い
- そもそもURLが間違えている
などの理由から、うまく取得ができないときがあります。
そんな時はどうなっちゃうでしょうか。
実際に、存在しないURL「https://tonari-it.com/not_exists」宛に実行してみましょうか。
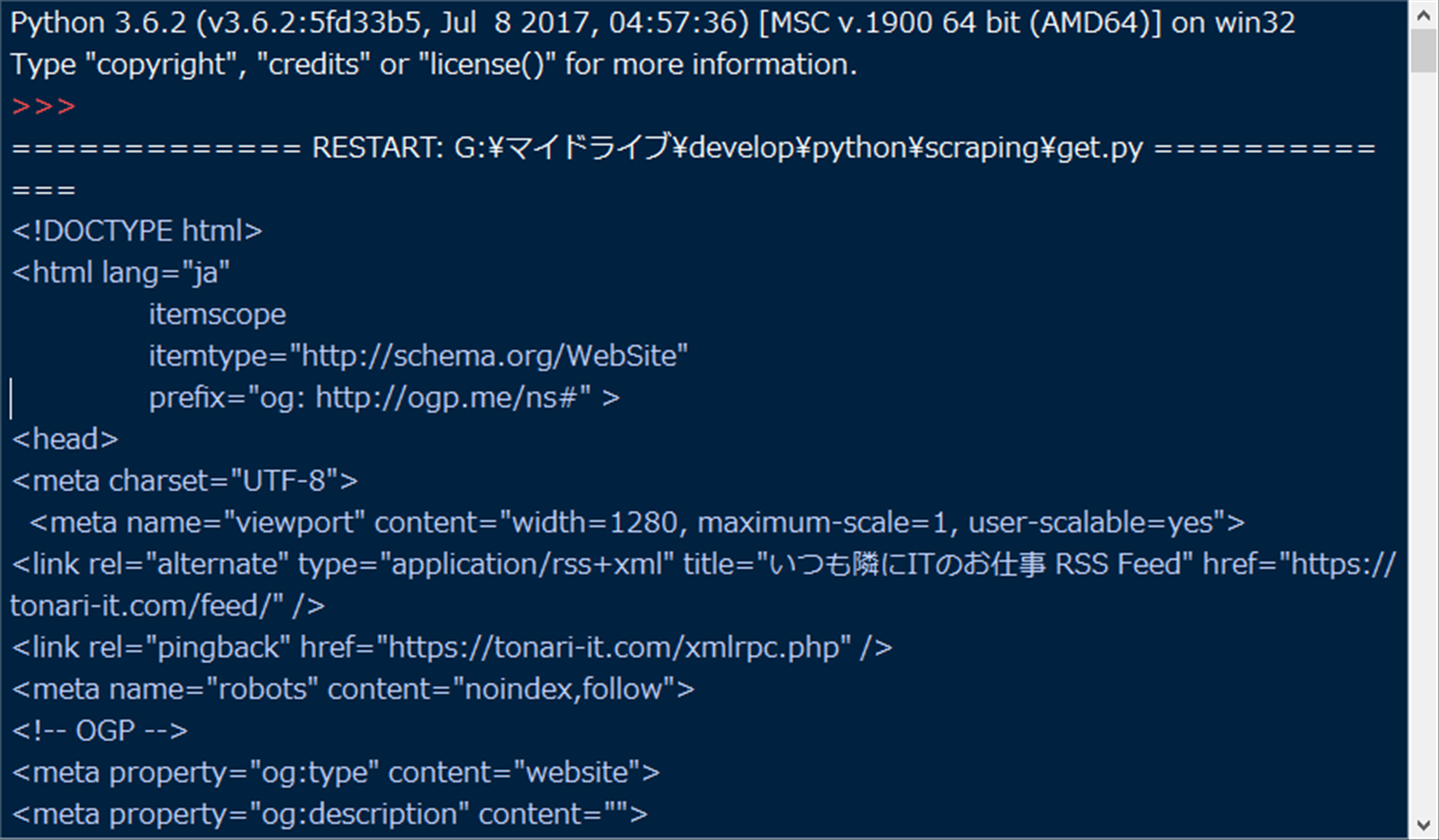
…おや、取得できちゃいました。
ですが、ちょっと眺めると
お探しのページは見つかりませんでした | Not_Exists
などとあります。実際に、ブラウザでこのURLを見てみると、いわゆる404ページでした。
ということで、なんか動くけど、正しい結果が得られていなかったというややこしい感じになっちゃいますね。
レスポンスのエラーをチェックして安全に中止する
それで、基本方針としては、どうせスクリプトが正しく動かないなら、より安全に中止させよう!というアイデアで進めていきます。というか、それが推奨されています。
というのも、きっとどこかで変な挙動になるのですが、それを起こすより前に、うまくいかなかったのを検知してそこで止めちゃったほうが、安全だし、対応すべきパターンが絞られるので対処もしやすいということになります。
HTTPステータスコードとは
まず、GETリスクエストに対して正しいレスポンスが得られたかどうか、というのはHTTPステータスコードなるもので確認をすることができます。
HTTPステータスコードというのは、通信をしている際の状態を表す3桁の数字で、大まかに以下のように分類されます。
- 100番台:処理中
- 200番台:成功
- 300番台:リダイレクト
- 400番台:クライアントエラー
- 500番台:サーバーエラー
requestsモジュールでget関数を使ったときにHTTPステータスコードを知るには、Responseオブジェクトのstatus_code属性を調べるという方法があります。
これで取得できます。
実際に、先ほどの存在しないページを使って、以下のようなスクリプトを実行してみると
import requests
res = requests.get('https://tonari-it.com/not_exists/')
print(res.status_code)
こんな出力が得られます。
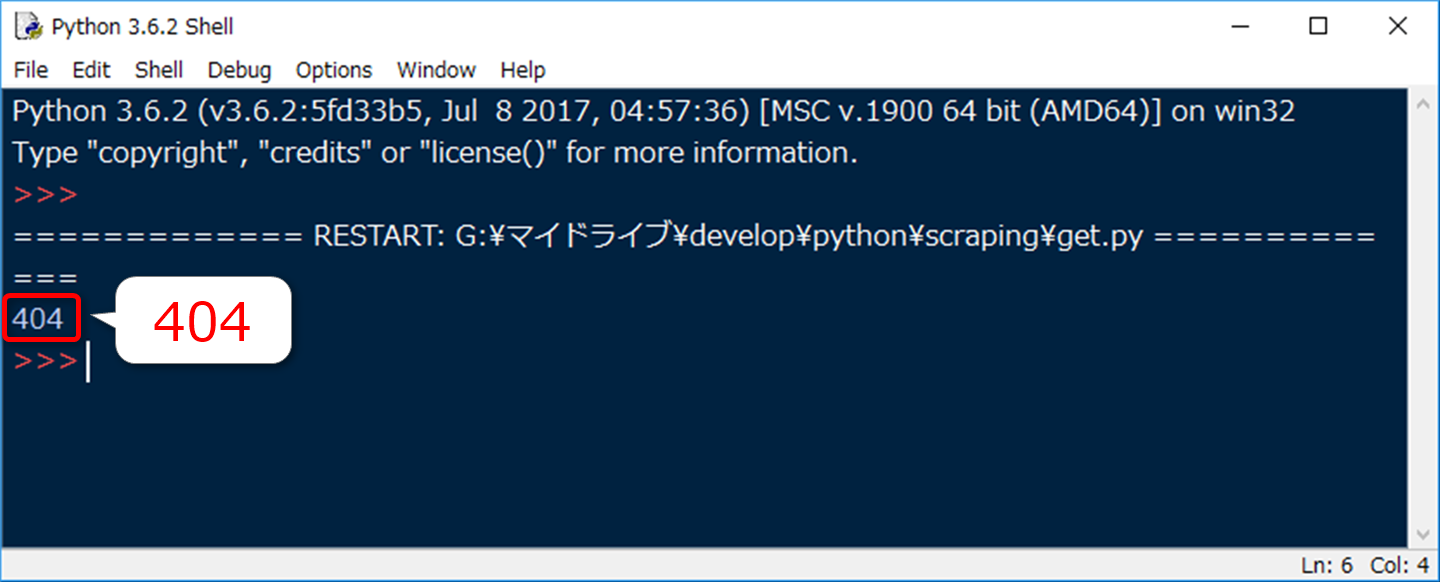
404。そのまんまですね。
raise_for_statusメソッドで例外を発生
このステータスコードが200番台以外であれば、止めちゃえ!ということになります。
Responseオブジェクトのstatus_code属性をif文などで判定して…という手もありますが、もっと簡単な方法が用意されています。
それが、Responseオブジェクトのraise_for_statusメソッドです。
Responseオブジェクトが持つステータスコードが200番台以外だったら、例外を起こす、つまりエラーメッセージを吐き出してスクリプトを停止します。
実際にやってみましょう。こちらのスクリプトです。
import requests
res = requests.get('https://tonari-it.com/not_exists/')
res.raise_for_status()
print(res.text)
実行結果はコチラ。
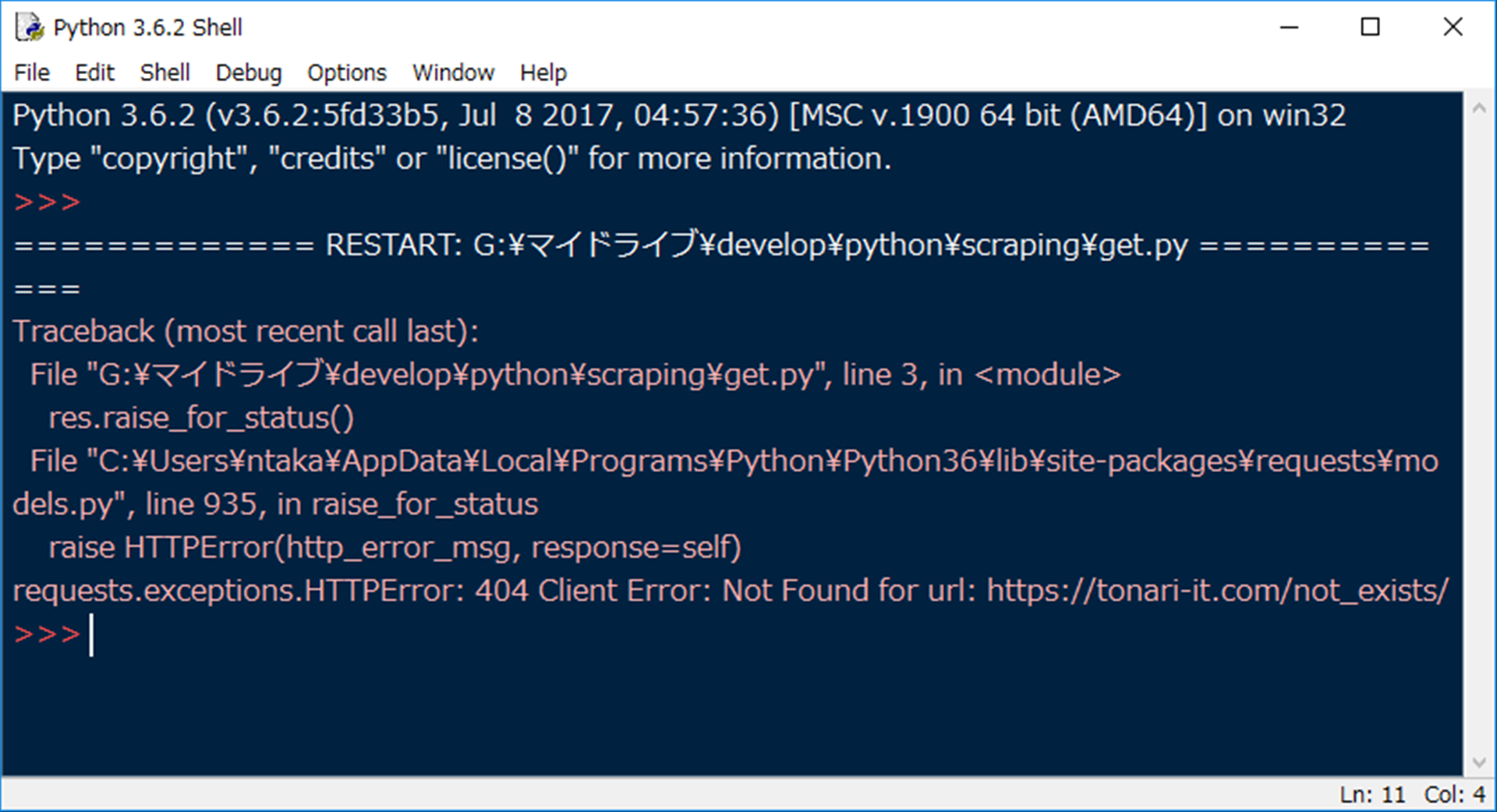
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://tonari-it.com/not_exists/
エラーが出て止まっちゃいますが、これでOK。
しかも、エラーメッセージがとっても親切。
まとめ
以上、PythonでWebページを取得できたかチェックする方法、またエラーの際に安全にスクリプトを中止する方法についてお伝えしました。
- HTTPステータスコードとResponseオブジェクトのstatus_code属性について
- Responseオブジェクトのraise_for_statusメソッドで例外を発生させる
本当は例外の発生をtry/except文でキャッチして分岐して…としたいところですが、それはまた別の機会にお伝えできればと思います。
次回は、いよいよHTMLの解析を進めていきます。

どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。