
photo credit: Carbon Arc Its days are numbered? -[ HMM ]- via photopin (license)
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者向け&Windowsユーザー向けのPythonでWebページのスクレイピングをする方法をお伝えしております。
前回の記事はコチラです。

Beautiful Soupモジュールを使って取得したWebページを解析する準備完了というところまでお伝えしています。
さて、いよいよ本格的にHTMLの解析をしていく必要があります。
解析…といってもどう進めていいものやら…というところもあるかも知れませんので、Chromeブラウザのデベロッパーツールを使いながら、その方法をお伝えしてきましょう。
まずは、PythonでWebページの特定のタグをまとめて取得する方法です。
では、行ってみましょう!
前回のおさらい
まずは、前回のおさらいから。
作ったスクリプトはコチラでした。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
print(soup.title)
- 当ブログのトップページについてrequestsモジュールのget関数で取得してきて
- そのレスポンスが正常かどうかチェック(正常でない場合は例外をスロー)
- そのHTML文字列からBeautifulSoupオブジェクトを生成
- titleタグの最初の要素を抽出して表示
と、こんなスクリプトです。
簡単なHTML解析として
とすることで、特定のタグ要素を取得できるのですが、取得できるのは最初に登場した一つの要素だけです。
title要素など、おそらくWebページごとに1つであろうタグの要素なら良いのですが、一般的には同じタグが複数存在しているので、その場合は使えません。
今回は、その点を解消していきます。
Chromeのデベロッパーツールについて
と、その前に、本来Webスクレイピングをする際には、欲しい情報がどんなタグに含まれているのかとか、どんな属性を持っているのかとか、つまりどんな条件で要素を取り出せば良いのかを知る必要があります。
その手段として、Google Chromeのデベロッパーツールを使わない手はありません。
欲しい情報を構成するHTML要素を確認する
解析したいWebページを開いて、ショートカットキー Ctrl + Shift + I または F12 キーを押下すると、デベロッパツールが起動します。
下図の「Select an element in the page to inspect it」のアイコンをクリックするか、ショートカットキー Ctrl + Shift + C でWebページ上に青い枠が出てくるようになります。
この状態で欲しい情報があるエリアをクリックすると、右側にのHTMLコードがワーって書いてあるところも連動して、そのエリアを示す箇所にフォーカスが当たります。

この機能を使えば、欲しいWebページの情報が、どんなHTMLで構成されているのかということがわかるのです。
欲しいHTML要素のouterHTMLをコピーする
それで、当ブログのトップページで言うと、記事一覧になっているのですが、その記事タイトルがh2タグで構成されているということです。
例えば、一つ例として記事タイトルのHTMLを取り出してみましょう。
この場合も、デベロッパーツールが便利です。
右側の欲しいHTML要素を選択した状態で、右クリック。表示されたメニューから「Copy」→「Copy outerHTML」とたどります。
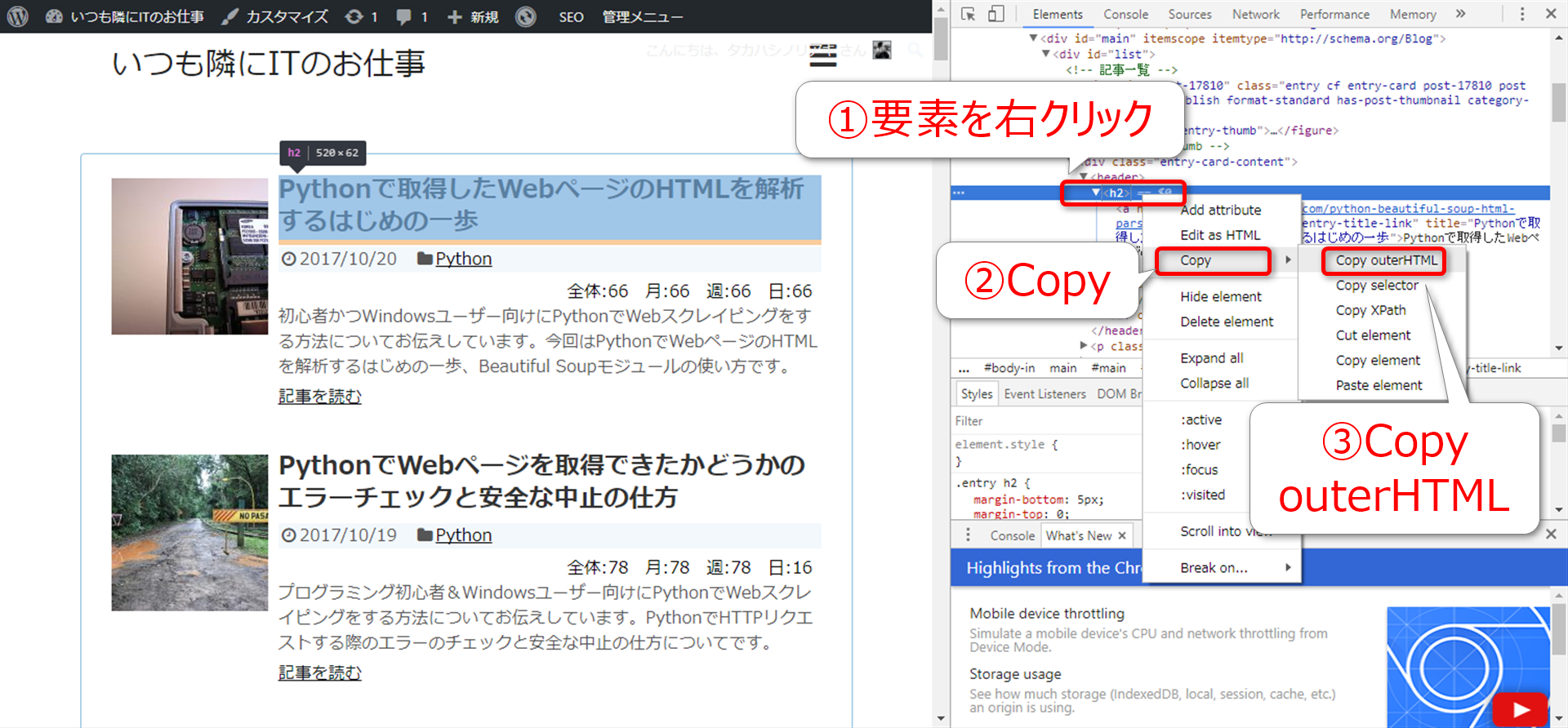
これで、outerHTMLつまり「タグも含めた外側のHTML文字列」がクリップボードにコピーされましたので、ペーストしてみましょう。
Pythonで取得したWebページのHTMLを解析するはじめの一歩
特定のタグの要素を取得する
ということで、今回のお題「ブログのトップページの記事一覧から記事タイトルを含むタグを取得したい」ということで進めていきますね。
BeautifulSoupオブジェクトのselectメソッド
Pythonでその目的を達成するためには、BeautifulSoupオブジェクトのselectメソッドを使う方法があります。
書き方はこちらです。
セレクタで指定した条件にマッチした要素を全て取得し、Tagオブジェクトのリストとして取得するのです。
Tagオブジェクトというのは、Beautiful Soupモジュールにおける、HTML要素を表現するオブジェクトです。
なお、セレクタというのは、CSSセレクタでのことで、いろいろな条件指定をすることができます。
例えば、h2タグを取得したければ
とします。他の使い方に関しては追ってお伝えしていきます。
ページ内の特定の要素を全て表示するスクリプト
では、これを使用して、ブログのトップページからh2要素を全て表示してみましょう。
スクリプトはコチラです。
import requests, bs4
res = requests.get('https://tonari-it.com')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('h2')
for elem in elems:
print(elem)
selectメソッドでは、Tagオブジェクトのリストが取得できますので、リストに対してfor文を回して全ての要素について表示をしています。
出力結果はコチラ。

ぶわーっと出てきちゃいましたが、うまくいっているようです。
まとめ
PythonでWebページ内の特定のタグ要素をまとめて取得する方法についてお伝えしました。
けっこう、半分以上Chromeのデベロッパーツールの話になってしまいましたが、スクレイピングをする上で有用ですので、ぜひ覚えておいていただければと思います。
次回は、class属性を条件にして、より色々な情報を取得できるようにしていきたいと思います。

どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。