
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者&Windowsユーザー向け、Pythonで辞書を使った集計ツールの作り方をお伝えしています。
前回の記事はこちら。

辞書に特定のキーがあるかどうかについて判定する方法をお伝えしました。
さて、これまでは集計する元のデータはリストとして用意していましたが、最初っからリストになっていてくれることはほとんどありません。
実際には、別の形式で与えられる場合が多いのですが、よくあるパターンは、そう。csvファイルですよね。
ということで、今回はcsvファイルのデータを辞書として集計する方法をお伝えします。
では、いってみましょう。
前回のおさらい
まずはおさらいから。
前回作成したスクリプトはこちらでした。
onigiris = ['シャケ', 'ツナ', 'ツナ', 'コンブ', 'シャケ', 'オカカ', 'シャケ', 'ツナ', 'コンブ', 'シャケ']
count = {}
for onigiri in onigiris:
count.setdefault(onigiri, 0)
count[onigiri] +=1
for key, value in count.items():
print('{}: {}'.format(key, value))
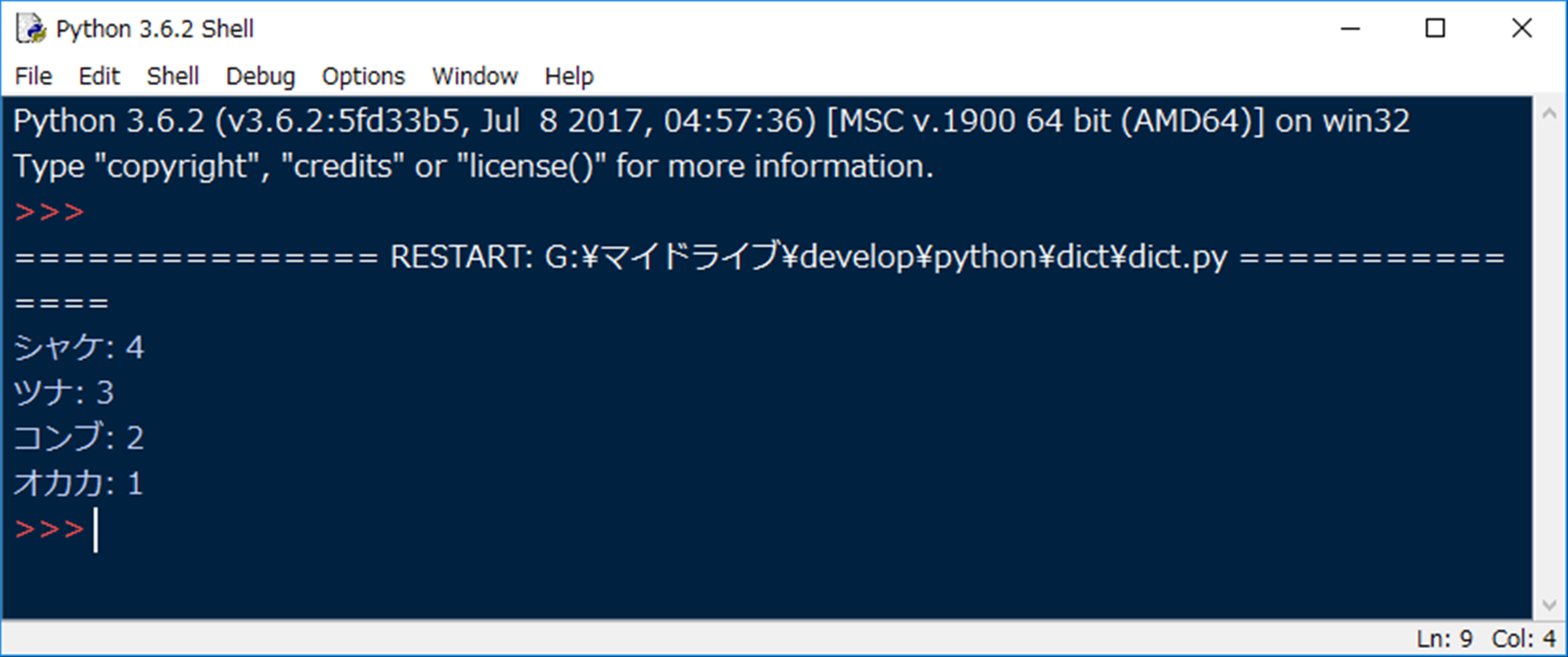
リストとしてまとめられているおにぎりの種類について、その登場回数を辞書として集計するというものでした。
3行目のfor文でリストのデータ全てについてループをします。
そして、ポイントは4行目。setdefaultメソッドで、辞書countにないキーが出てきたら、新たにそのキーを追加しその値を0とするという部分です。
結果として、以下のような出力が得られます。
csvファイルのデータを集計する
今回は与えるデータを、リストではなく、以下のようなcsvファイルとしたいと思います。
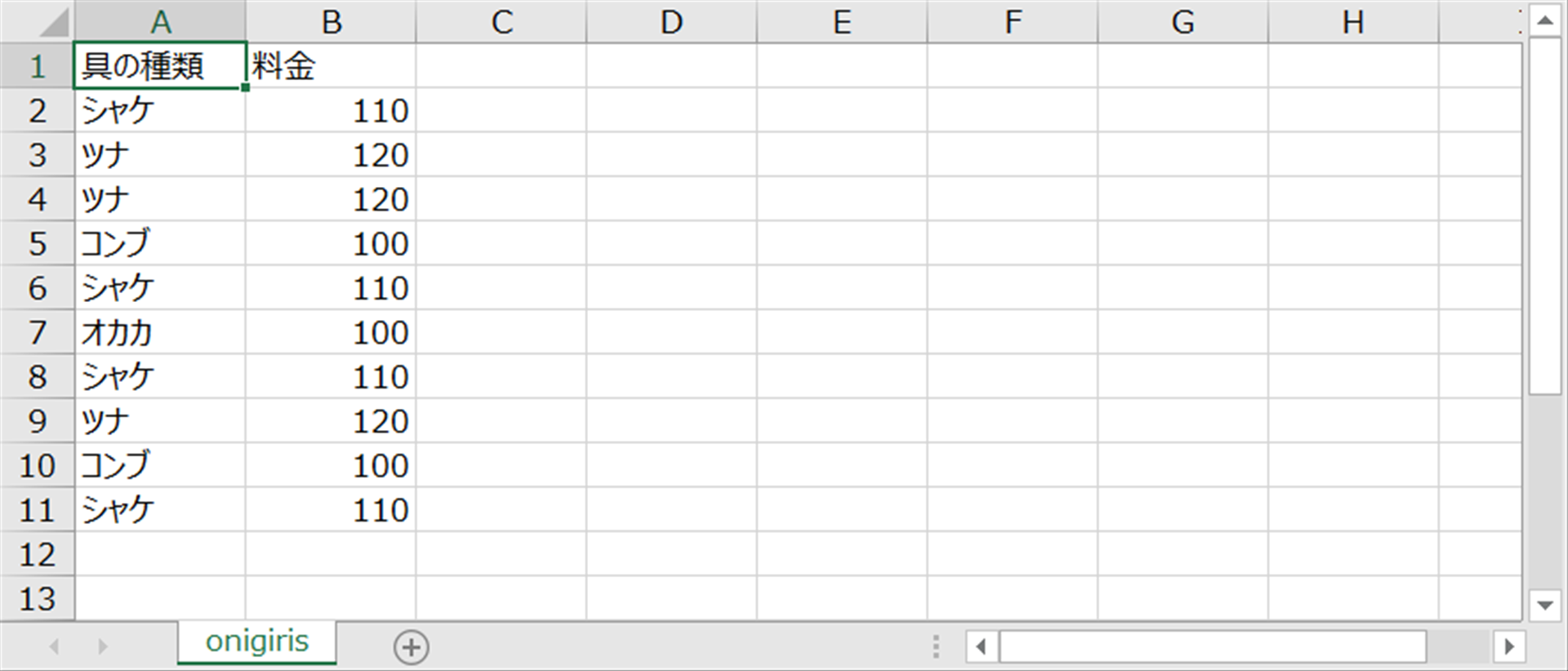
1列目におにぎりの具の種類、2列目に料金が入力されている「onigiris.csv」というファイル名のcsvファイルです。
まず、これまでと同様に、おにぎりの具の種類について登場した回数をカウントするスクリプトを作っていきましょう。
csvファイルのデータを読み取る
csvファイルを開いてデータを読み取る方法は、以下の記事で紹介しています。

ポイントは以下です。
まず、ファイルを開くにはopen関数を使います。今回は、読み取りで開きますのでmodeは省略して読み取りモードとします。
# 処理
次に、csvファイルのデータをPythonで扱う形式であるReaderオブジェクトとして取得します。csvモジュールのreader関数を使いますね。
このReaderオブジェクトが取得できれば、以下の書式で行単位でループを回すことができます。
# 処理
これで、各行をリストとして取得できるので、必要な列の値をインデックスを指定して取り出せばOKです。
csvファイルのデータを集計するスクリプト
以上を踏まえて、以下のようなスクリプトを作成しました。
import csv
count = {}
with open('onigiris.csv') as f:
reader = csv.reader(f)
for row in reader:
onigiri = row[0]
count.setdefault(onigiri, 0)
count[onigiri] +=1
for key, value in count.items():
print('{}: {}'.format(key, value))
では、実行してみましょう。
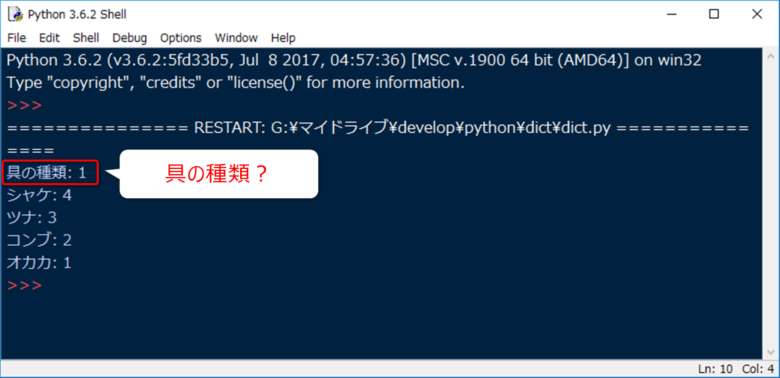
おや…具の種類?
csvファイルの1行目、見出し行のデータもカウント対象になってしまいました。
見出し行は飛ばしたいですね…。
next関数でcsvの見出し行を飛ばす
はい、Pythonにはそのままズバリ行を飛ばすメソッドが存在しています。next関数です。
next関数を使うと、Readerオブジェクトの読み取る行を現在の次の行に移します。
書き方はこちら。
ちなみに、戻り値として飛ばした行のリストを取得します。
見出し行を飛ばしてcsvファイルのデータを集計する
next関数を使って先ほどのスクリプトを修正しました。
こちらです。
import csv
count = {}
with open('onigiris.csv') as f:
reader = csv.reader(f)
header = next(reader)
print(header)
for row in reader:
onigiri = row[0]
count.setdefault(onigiri, 0)
count[onigiri] +=1
for key, value in count.items():
print('{}: {}'.format(key, value))
5行目にnext関数を1回入れていますので、見出し行を飛ばして集計をすることができます。
また、ついでに6行目でnext関数で取得した見出し行のリストを表示しています。
実行結果は…
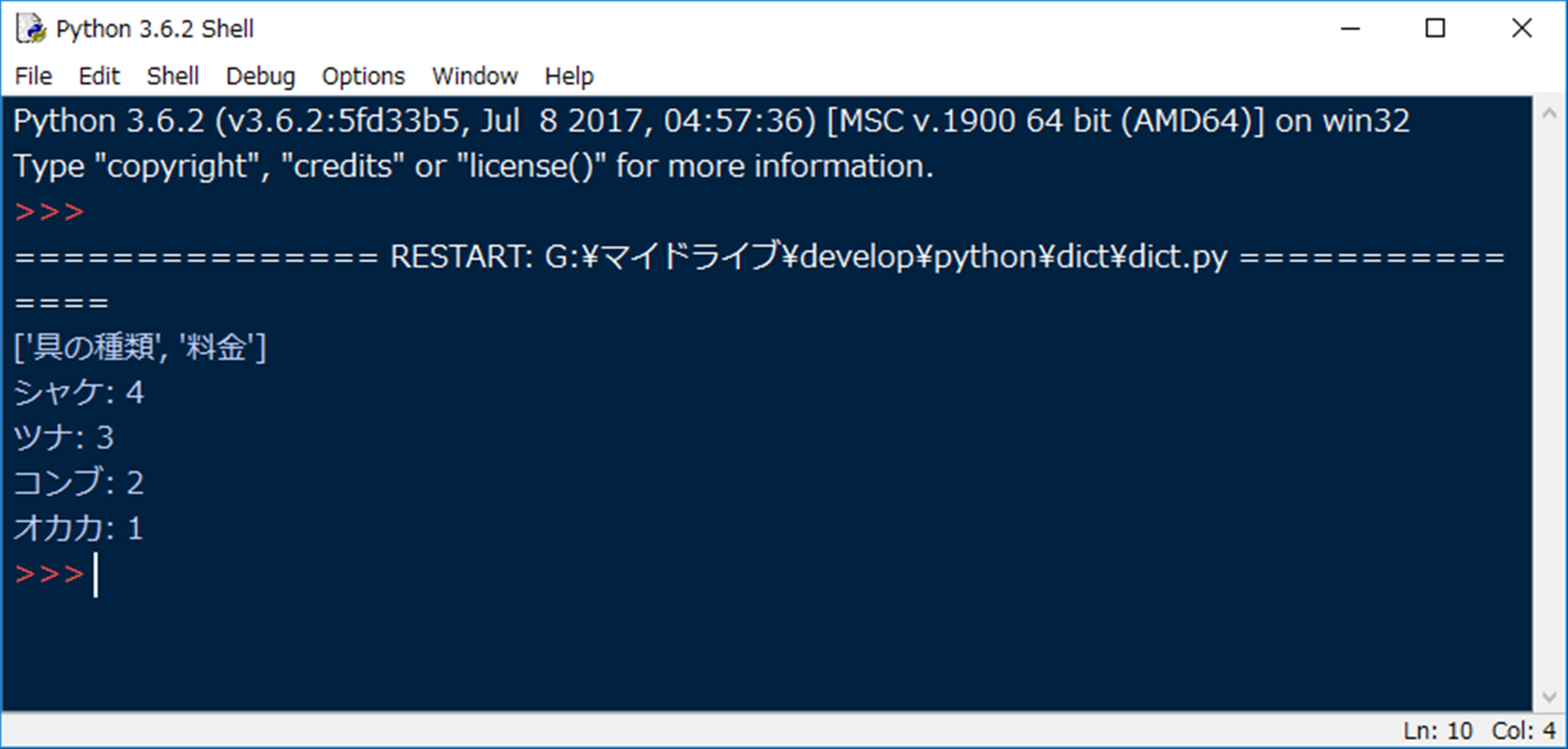
となります。
まとめ
Pythonでcsvファイルのデータを辞書データとして集計する方法をお伝えしました。
- csvファイルのデータを取得する
- next関数で行を飛ばす
Pythonはデータ分析に強いそうですから、その初歩の初歩のテクニック…ということになるのではないかと期待しています。
今回はいわゆる「COUNTIF」のような処理でしたが、次回はcsvファイルから「SUMIF」をしたいと思います。
どうぞお楽しみに!
連載目次:初心者向けPythonで辞書を使った集計ツールの作り方
Pythonの「辞書」を使うことで、カウントや計算などの集計作業を簡単に行うことができます。本シリーズでは、辞書とは何かというところから実際にcsvファイルを集計するツールを作るところまでを伝えしていきます。

