photo credit: PeterThoeny Bumper to bumper via photopin (license)
みなさん、こんにちは!
タカハシ(@ntakahashi0505)です。
初心者向け&Windowsユーザー向けにPythonでWebスクレイピングをする方法をお伝えしています。
前回はコチラの記事でした。

WebページのHTMLからclass属性によって要素を取得する方法でした。
ですが、HTML解析をする上で、class属性だけではちょっと物足りない。
ということで、今回は別の方法をお伝えしていきますよ。id属性を使います。
では、PythonでWebページからid属性を条件にして要素を取得する方法、行ってみましょう。
前回のおさらい
では、前回のおさらいから行きます。
作成したスクリプトはコチラでした。
import requests, bs4
res = requests.get('https://tonari-it.com';;)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('.entry-title.entry-title-link')
for elem in elems:
print(elem)
当サイトのトップページの記事タイトル一覧から、記事タイトルを含む要素を取得するスクリプトです。
requestsモジュールを使ってHTMLをgetしてきて、Beautiful Soupモジュールで解析して、class属性として「entry-title entry-title-link」を持つ要素を取得しています。
このページにおいてはこの方法で確かに目的の要素が取得できていますので、問題ないといえば問題ないのですが、class属性だけではうまく取得できないときも実際にあり得ます。
ですので、確実に目的の要素を取得できるように、別の方法も見ていきましょう。
特定のid属性を持つ要素を取得する
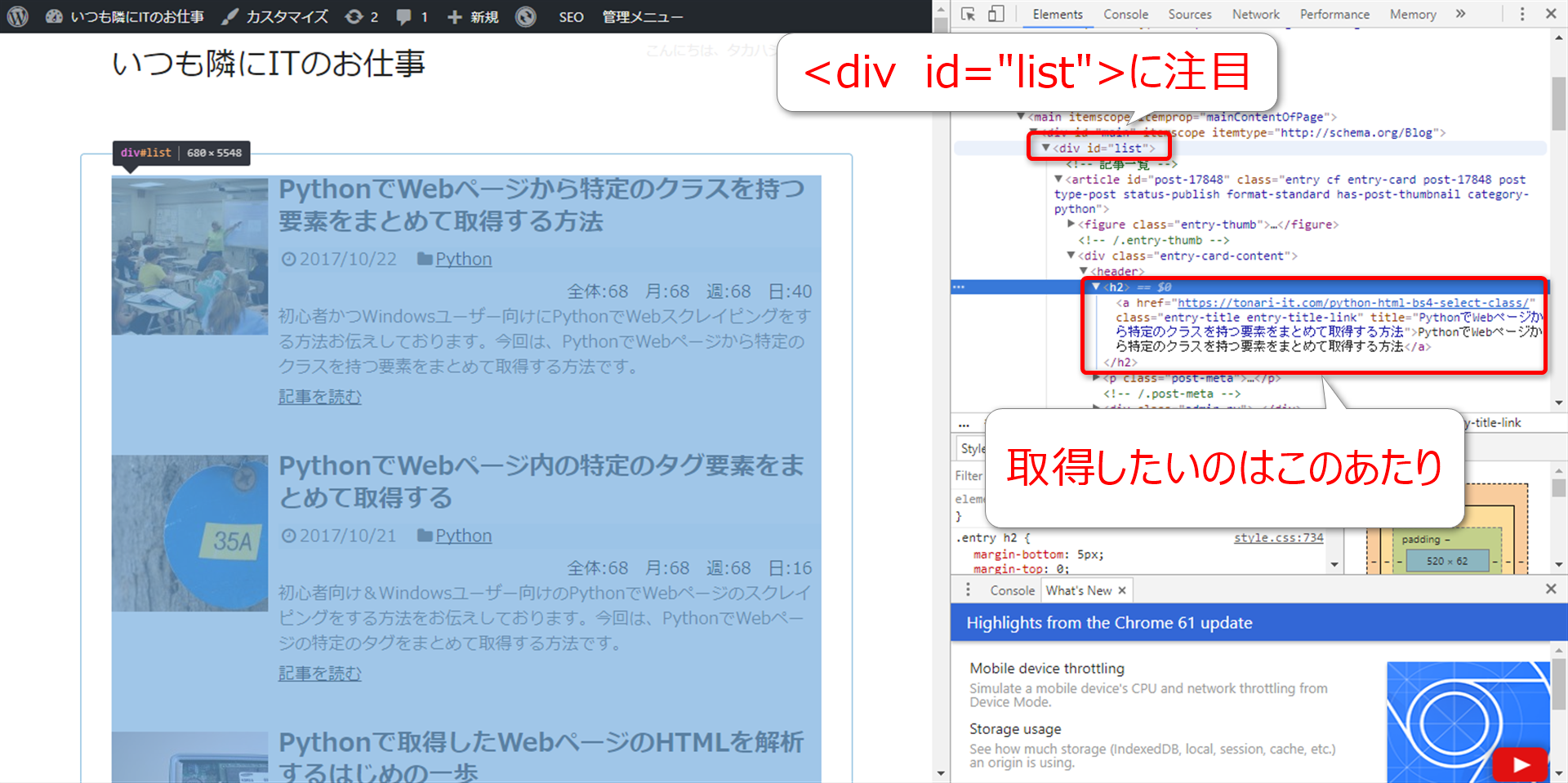
そこで注目するのは、以下図にある
の「id」という属性が付与されている部分です。
取得したい要素よりもだいぶ上の階層だな~なんて思われるかも知れませんが、実はけっこう有効です。
id属性とは
というのも、この「id=」から始まるパラメータは、id属性といいまして、HTML解析において超強力な道しるべになります。また、id属性の値をID名といいます。
id属性の定義を調べてみますと
id属性(identifier)は要素を識別するために固有の ID名(識別子)をつけます。ひとつの文書内で同一の ID名を複数つけること(重複)はできません(つまり、一意でなければならない)。id属性を指定する主な目的はスタイルシート(CSS)のセレクタ(スタイルを適用する対象の目印のこと)にしてスタイリングや、スクリプト(JavaScript)で特定要素を参照してスクリプティングを行うための手段として使われます。
とあります。重要なのは、「ひとつの文書内で同一の ID名を複数つけること(重複)はできません」というところです。
つまり、同じWebページに、とあるid属性を持つ要素は一つしかないのです。
class属性は複数の要素が持つ可能性がありました。複数を取得したいときは便利なのですが、その中からさらに絞り込む必要があるときは面倒です。
ですが、欲しい要素がid属性さえ持っていれば、最短距離でその要素を取得できるのです。
id属性を条件に要素を取得する
id属性を条件に要素を取得するセレクタは以下の通りです。
#ID名シンプルですね。
ですから、前述の「id=”list”」の要素を取得するには、selectメソッドを
elems = soup.select('#list')とすればよいということになります。
記事タイトルの要素を取得する
ですが、今回ほしいのは、ID名「list」を持つdiv要素の中に含まれる、h2タグの要素だったりします。
その場合は、「~要素の中の~要素」というように、特定の要素の下の階層のみを対象にして要素を取得するような指定をします。
セレクタとしては、以下のようにセレクタとセレクタを半角スペースでつなげるだけです。
セレクタ1 セレクタ2これでセレクタ1が示す要素の下の階層のうち、セレクタセレクタ2が示す要素、という意味になります。
ですから「id=”list”」を持つ要素の配下のh2タグを持つ要素であれば
elems = soup.select('#list h2')となるわけです。
記事タイトルの要素を取得するスクリプト
それで、実際のスクリプトはこちらになります。
import requests, bs4 res = requests.get('https://tonari-it.com') res.raise_for_status() soup = bs4.BeautifulSoup(res.text, "html.parser") elems = soup.select('#list h2') for elem in elems: print(elem)このスクリプトを実行すると、以下のように対象となる要素が出力されます。
まとめ
PythonでWebページからid属性を条件にして要素を取得する方法についてお伝えしました。
- id属性とは何か
- 特定のID名を持つ要素についてのセレクタの書式
- 特定の要素の配下を対象に要素を取得する場合のセレクタの書式
これで、タグ、class属性、id属性を条件に要素を取得することができました。他にもいくつか方法がありますが、基本としてはこれくらいでまあまあのHTML解析はいけると思います。
では、続いて取得した要素から、テキストやURLなどを取り出す方法をお伝えします。
どうぞお楽しみに!
連載目次:初心者向け!PythonでWebスクレイピングをしよう
スクレイピングとはWebサイトから情報を集めてくること。Pythonは専用の書籍が出るくらいスクレイピングが得意です。本シリーズでは、PythonでWebスクレイピングをする方法をお伝えしていきます。