
みなさん、こんにちは!うえはら(@tifoso_str)です。
【JavaScriptで動作するWebページを色々な言語でスクレイピング】するシリーズの第五弾です。
前回はGASでPhantomJSを利用してWebページをスクレイピングしました。

HTMLドキュメントを取得するところまでできたので、今回はHTMLドキュメントの中からmatchメソッドと正規表現を使って目的の値を取得してみます。
前回までのおさらい
GASでJavaScriptで動作するWebページをスクレイピングするにはPhantomJS Cloudを利用する必要があります。
Phantom Js Cloudはクラウドで動作するヘッドレスブラウザで、簡単に言うと、スクレイピングしたいURLをわたすと、JavaScriptが実行された後のHTMLドキュメントを返してくれるサービスです。
GASでPhantomJSを利用してWebページをスクレイピングするスクリプトは下記のようになります。
function scraping() {
const URL = 'https://www.eb.pref.okinawa.jp/kassui/';//沖縄県企業局のダム貯水率
var key = '**-#####-*****-#####-*****-#####';
var option =
{url:URL,
renderType:"HTML",
outputAsJson:true};
var payload = JSON.stringify(option);
payload = encodeURIComponent(payload);
var url = "https://phantomjscloud.com/api/browser/v2/"+ key +"/?request=" + payload;
var response = UrlFetchApp.fetch(url);
var json = JSON.parse(response.getContentText());
var source = json["content"]["data"];
Logger.log(source);
}
ログを確認すると、下記のようになります。

matchメソッドと正規表現を利用して目的の値を取得する
上記でHTMLドキュメントを、取得できることを確認しました。
あとは、matchメソッドと正規表現をうまく使えば目的の値を取得できます。
matchメソッドについて
特定の文字列を検索するときにはmatchメソッドを使用します。
検索条件に一致した場合、抽出された文字列は配列に格納されます。
もし、一致する文字列がない場合の戻り値はnullとなりますので、場合によってはエラー処理が必要になります。
また、検索条件に正規表現を用いることで、色々な文字列を柔軟に検索することが出来ます。
正規表現について
正規表現には、正規表現リテラルで表記する方法とRegExpオブジェクトを使う方法があります。
今回は、よく使われる正規表現リテラルを使用します。
正規表現リテラルは、スラッシュ(/)で囲んで表記します。
正規表現のメタ文字と用法は多数ありますので、スクレイピングするときによく使うものを紹介します。
スクレイピングするときには、特定のタグに囲まれた文字列をよく検索します。
例えばタイトルは下記のようになっています。
<title>ダム貯水率 | 安全・安心な水を届ける沖縄県企業局</title>
<title>と</title>で囲まれている部分を取得できればいいわけで、その場合、下記のように表記します。
var myRegexp = /<title>([\s\S]*?)<\/title>/;
それぞれのメタ文字の意味は下記の通りです。
| 文字 | 機能 |
|---|---|
| () | グループ |
| [] | 角括弧内のいずれかの1文字 |
| \s | 空白文字 |
| \S | 空白以外の文字 |
| * | 直前の文字が0文字以上 |
| ? | 直前の文字が0文字または1文字以上 |
ここで、「?」は単独では上の意味ですが、他のメタ文字の直後に指定した場合、最短の文字列とマッチするように制限します。
今回のメタ文字は、空白文字と空白以外の文字列が0文字以上繰り返される最短の文字列と一致する、という意味になります。
あとは、matchメソッドを合わせて、下記のようなスクリプトで、タイトル部分を取得できます。
var myRegexp = /<title>([\s\S]*?)<\/title>/; var title = source.match(myRegexp);
最短の文字列とマッチするように制限する理由
ここで、なぜ「?」をつけて最短の文字列とマッチするように制限しているか疑問があると思います。
上の例のタイトルは、HTMLドキュメントの中に一つしかないので無くても問題ないのですが、貯水率を取得する部分を見るとその理由がわかります。
貯水率の部分のHTMLドキュメントは下記のようになっています。
(関係ない行は省略しています。)
<table summary="ダム貯水率状況" width="100%">
<tbody>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>
<th class="caution_bg_03">本日の貯水率(%)</th>
<td align="right" id="ritsu_today1">84.2</td>
<td align="right" id="ritsu_today2">89.4</td>
<td align="right" id="ritsu_today3">98.7</td>
<td align="right" id="ritsu_today4">84.6</td>
</tr>
<tr>
<th class="caution_bg_03">平年値(%)(※1)</th>
<td align="right" id="ave1">81.7</td>
<td align="right" id="ave2">86.8</td>
<td align="right" id="ave3">90.0</td>
<td align="right" id="ave4">82.2</td>
</tr>
<tr>...</tr>
</tbody>
</table>
本日の貯水率を取得する場合、「id=”ritsu_today4″>」と「</td>」で囲まれた部分を検索するようにします。
はじめの「id=”ritsu_today4″>」は一つですが、後ろの「</td>」は複数あります。
「?」を付けないと、空白文字と空白以外の文字列が0文字以上繰り返される最長の文字列と一致する条件となるので、一番最後の「</td>」まで抽出されてしまいます。
これでは都合がよくないですよね。
このような理由から、目的の部分を効率よく抽出するために「?」をつけて、最短の文字列とマッチするように制限しています。
GASとPhantomJs CloudでJavaScriptで動作するページから目的の値を取得するスクリプト
今までのスクリプトをまとめると下記のようになります。
function scraping() {
const URL = 'https://www.eb.pref.okinawa.jp/kassui/';//沖縄県企業局のダム貯水率
var key = '**-#####-*****-#####-*****-#####';
var option =
{url:URL,
renderType:"HTML",
outputAsJson:true};
var payload = JSON.stringify(option);
payload = encodeURIComponent(payload);
var url = "https://phantomjscloud.com/api/browser/v2/"+ key +"/?request=" + payload;
var response = UrlFetchApp.fetch(url);
var json = JSON.parse(response.getContentText());
var source = json["content"]["data"];
var myRegexp = /<title>([\s\S]*?)<\/title>/;
var title = source.match(myRegexp);
Logger.log(title[1]);
var myRegexp = /<span id=\"chosui_hiduke\">([\s\S]*?)<\/span>/;
var day = source.match(myRegexp);
Logger.log(day[1]);
var myRegexp = /id=\"ritsu_today4\">([\s\S]*?)<\/td>/;
var waterRate = source.match(myRegexp);
Logger.log(waterRate[1]);
}
前々回で、検索にマッチした結果の中身の部分が配列の2番目に入ることがわかったので、各ログ出力の部分で利用しています。
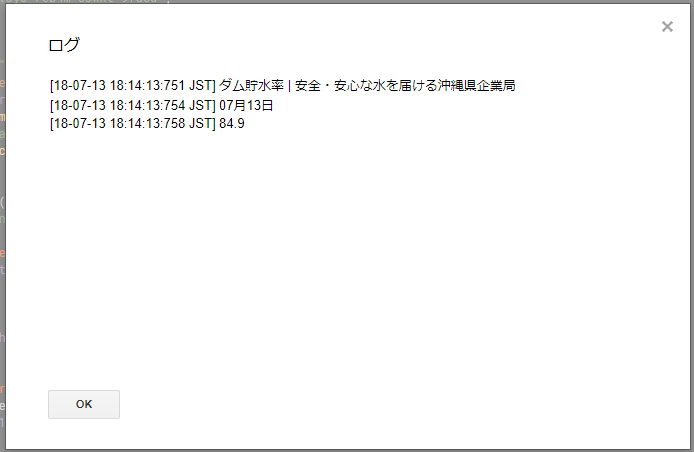
はい、ちゃんと値を取得できました!
まとめ
今回は、HTMLドキュメントの中からmatchメソッドと正規表現を使って目的の値を取得してみました。
正規表現は難しいと思いますので、少しずつ覚えていくといいと思います。
PhantomJs Cloud使って、正規表現使いこなせれば、スクレイピングは怖いものなしですかね?
次回は、GASに変わってpythonとPhantomJs Cloudを利用してJavaScriptで動作するWebページをスクレイピングしてみます。

お楽しみに!
連載目次:JavaScriptで動作するWebページを色々な言語でスクレイピング
Webスクレイピングしていて、値が取得できないということはありませんか?
そんな時は、Webサイトの表示にJavaScriptを利用しているからです。
本連載では、色々な言語でその対応をご紹介します!
- GASやVBAでスクレイピングができない理由として考えるべきJavaScriptのこと
- VBAでIEを操作してJavaScriptで動作するWebページをスクレイピング
- GASでJavaScriptで動作するWebページをスクレイピングするPhantomJsとは
- GASでPhantomJSを利用してWebページをスクレイピング
- GASでスクレイピングしたデータからmatchメソッドと正規表現を使って目的の値を取得
- PythonでPhantomJs Cloudを利用してWebページをスクレイピング
- PythonとPhantomJs CloudでスクレイピングしたデータをBeautifulSoupで解析

