
みなさん、こんにちは!うえはら(@tifoso_str)です。
【JavaScriptで動作するWebページを色々な言語でスクレイピング】するシリーズの第七弾です。
前回は、「PythonでPhantomJs Cloudを利用してWebページをスクレイピング」しました。

GASと同じように色々な関数があるので、Pythonでも同じような書き方で実行出来ることがわかりました。
GASの場合、この後の処理はJSON形式のパース、matchメソッドと正規表現を使用して目的の値を取得する、という流れでした。
Pythonの場合も同じように、とやってもいいのですが、Pythonにはサードパーティ製のライブラリが豊富にあるので、少し楽できる方法をご紹介します。
今回は、Beautiful Soupというモジュールを利用して、目的のデータを取得していきます。
前回の確認
Beautiful Soupを使う前に前回のおさらいです。
PythonとPhantomJs Cloudでスクレイピングするコードは下記のようになりました。
import json
import urllib.parse
import requests
payload = {'url':'https://www.eb.pref.okinawa.jp/kassui/','renderType':'HTML','outputAsJson':'true'}
payload = json.dumps(payload) #JSONパース
payload = urllib.parse.quote(payload,safe = '') #URIエンコード
key = '**-#####-*****-#####-*****-#####'
url = "https://phantomjscloud.com/api/browser/v2/"+ key+"/?request=" + payload
response = requests.get(url) #GETリクエスト
print(response.text)
リクエスト部分をJSON形式に変換して、URIエンコードしました。
また、URIエンコードするときに「/」スラッシュもエンコードする必要があるので、オプションで指定しました。
GETリクエストして返ってきた実行結果は下記のようでしたね。
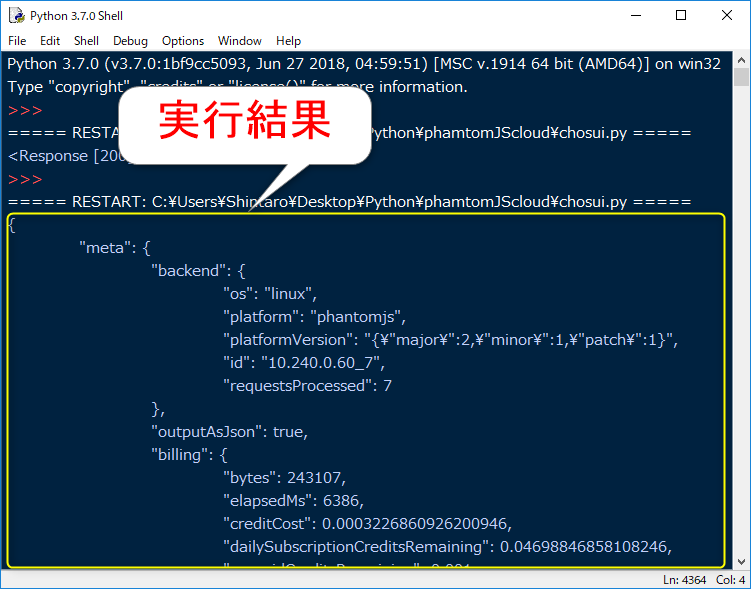
GASのときと同じようにデータ取得できたので、次の処理へ移っていきます。
JSON形式から辞書型へ変換
Beautiful Soupを使う前にもう少し準備が必要です。
PhantomJs Cloudから返ってきたデータはJSON形式なので、Pythonで扱いやすいように辞書型に変換する必要があります。
JSON形式から辞書型への変換はJSONモジュールを使うのが一般的かもしれませんが、GETリクエストの時に利用したrequestsモジュールでもできます。
今回は、requestsモジュールを使ってみます。
requestsモジュールでJSON形式から辞書型への変換にはjson関数を使い、書き方は下記のようになります。
はい、とっても簡単ですね!
また、GASで実行したときに「content」の「data」にあることがわかっているので、コードにすると下記のようになります。
import json
import urllib.parse
import requests
key = '**-#####-*****-#####-*****-#####'
payload = {'url':'https://www.eb.pref.okinawa.jp/kassui/','renderType':'HTML','outputAsJson':'true'}
payload = json.dumps(payload) #JSONパース
payload = urllib.parse.quote(payload,safe = '') #URIエンコード
url = "https://phantomjscloud.com/api/browser/v2/"+ key+"/?request=" + payload
response = requests.get(url) #GETリクエスト
responseDict = response.json()
html = responseDict["content"]["data"]
print(html)
実行結果を確認すると以下のようになります。
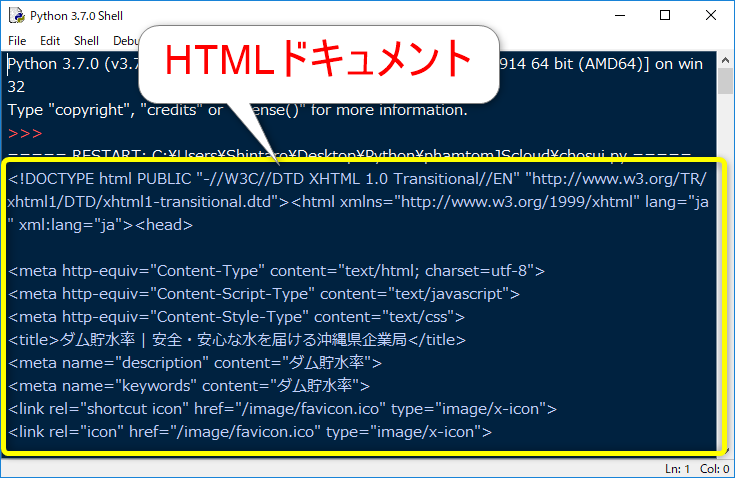
つらつらとHTMLドキュメントが取得できたと思います。
Beautiful Soupを使って目的の値を取得
HTMLドキュメントが取得できたので、いよいよBeautiful Soupモジュールを使っていきます。
Beautiful Soupモジュールは標準ライブラリではないので、インストールが必要です。
Beautiful Soupモジュールのインストール等は下記の記事で紹介しているので、こちらをご覧下さい。

HTMLドキュメントを解析するには、まず、HTMLドキュメントからBeautifulSoupオブジェクトを作成する必要があります。
この作業をBeautiful Soupのドキュメントでは、スープの作成と呼んでいます。(本当です!)

BeautifulSoupオブジェクト(スープ)の作成は下記のようになります。
パーサーの部分でどのような形式で解析するか決めます。
lxmlやhtml5libという形式がありますが、今回は標準ライブラリのhtml.parserを使用します。
実際には下記のようなコードになります。
soup = bs4.BeautifulSoup(html, "html.parser")
BeautifulSoupオブジェクト(スープ)が作成できたら、あとは目的の値を取得するだけです。
タイトルの取得
まずは、タイトルを取得してみます。
BeautifulSoupオブジェクトから特定のタグ要素を取得するには、下記のようになります。
タイトルを取得するにはタグ名を「title」にすればいいので、コードは下記のようになります。
import json
import urllib.parse
import requests
import bs4
key = '**-#####-*****-#####-*****-#####'
payload = {'url':'https://www.eb.pref.okinawa.jp/kassui/','renderType':'HTML','outputAsJson':'true'}
payload = json.dumps(payload) #JSONパース
payload = urllib.parse.quote(payload,safe = '') #URIエンコード
url = "https://phantomjscloud.com/api/browser/v2/"+ key+"/?request=" + payload
response = requests.get(url) #GETリクエスト
responseDict = response.json()
html = responseDict["content"]["data"]
soup = bs4.BeautifulSoup(html, "html.parser")
print(soup.title)
実行してみます。
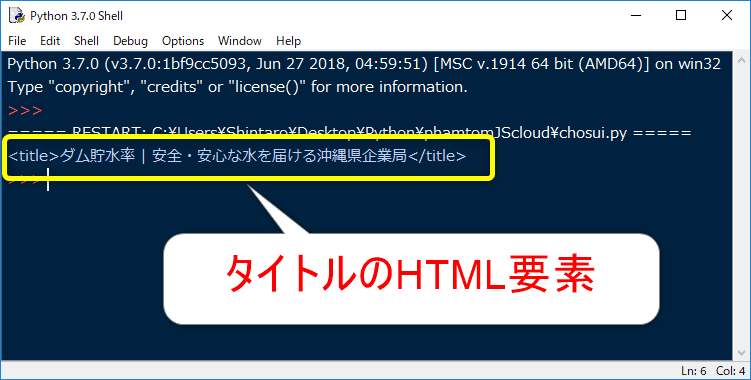
取得できましたが、これは、HTML要素を表すTagオブジェクトです。
実際には、テキスト部分を抜き出したいですよね!
そんなときは、追加でgetTextメソッドを使用します。
先程のコードの20行を下記のように変更します。
print(soup.title.getText())
実行すると、下記のようにタグの中身だけを抜き出せます。
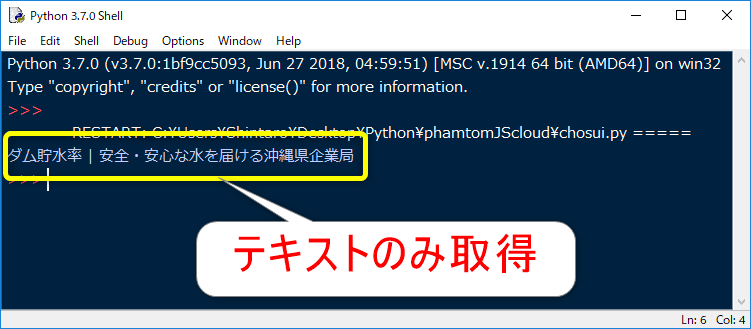
id属性で値を取得
次はid属性で値を取得してみます。
id属性は一つのページに一つしかないので、id属性がわかっていれば、簡単に値を取得できます。
BeautifulSoupオブジェクトからCSSセレクタを使って、Tagオブジェクトを取得するにはselectメソッドを使用します。
id属性から取得するには下記のようになります。
今回は日付のidは「chosui_hiduke」貯水率のidは「ritsu_today4」なので、コードは下記のようになります。
import json
import urllib.parse
import requests
import bs4
key = '**-#####-*****-#####-*****-#####'
payload = {'url':'https://www.eb.pref.okinawa.jp/kassui/','renderType':'HTML','outputAsJson':'true'}
payload = json.dumps(payload) #JSONパース
payload = urllib.parse.quote(payload,safe = '') #URIエンコード
url = "https://phantomjscloud.com/api/browser/v2/"+ key+"/?request=" + payload
response = requests.get(url) #GETリクエスト
responseDict = response.json()
html = responseDict["content"]["data"]
soup = bs4.BeautifulSoup(html, "html.parser")
print(soup.title.getText())
print(soup.select('#chosui_hiduke').getText())
print(soup.select('#ritsu_today4').getText())
実行してみます。
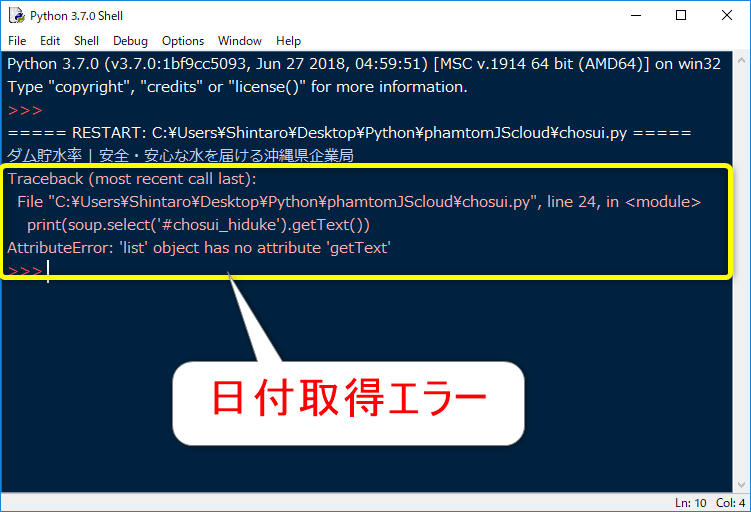
あれ、エラーが出てしまいましたね。
エラー内容を確認すると、「リストオブジェクトにはgetTextメソッドは使用できません。」となっています。
selectメソッドは複数の値を取得できるように、リスト形式でデータが返ってくるんですね。
リストであることを考慮してコードを修正します。
import json
import urllib.parse
import requests
import bs4
key = '**-#####-*****-#####-*****-#####'
payload = {'url':'https://www.eb.pref.okinawa.jp/kassui/','renderType':'HTML','outputAsJson':'true'}
payload = json.dumps(payload) #JSONパース
payload = urllib.parse.quote(payload,safe = '') #URIエンコード
url = "https://phantomjscloud.com/api/browser/v2/"+ key+"/?request=" + payload
response = requests.get(url) #GETリクエスト
responseDict = response.json()
html = responseDict["content"]["data"]
soup = bs4.BeautifulSoup(html, "html.parser")
print(soup.title.getText())
print(soup.select('#chosui_hiduke')[0].getText())
print(soup.select('#ritsu_today4')[0].getText())
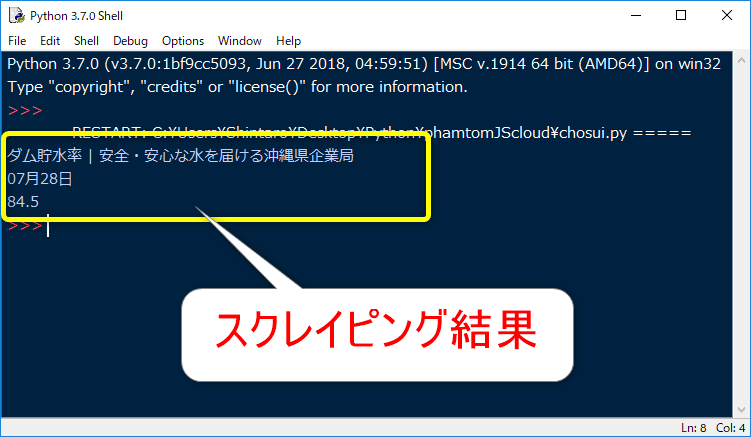
はい、無事に目的の値を取得できました。
まとめ
今回はPythonとPhantomJs CloudでスクレイピングしたデータをBeautifulSoupで解析しました。
GASでは正規表現とmatch関数を使用した部分を、PythonではBeautifulSoupを利用することで、コードをスッキリとすることが出来ました。
VBA,GAS,Pythonと3つの言語でスクレイピングしました。
使いやすい言語で、スクレイピングにチャレンジしてみて下さい!
連載目次:JavaScriptで動作するWebページを色々な言語でスクレイピング
Webスクレイピングしていて、値が取得できないということはありませんか?
そんな時は、Webサイトの表示にJavaScriptを利用しているからです。
本連載では、色々な言語でその対応をご紹介します!
- GASやVBAでスクレイピングができない理由として考えるべきJavaScriptのこと
- VBAでIEを操作してJavaScriptで動作するWebページをスクレイピング
- GASでJavaScriptで動作するWebページをスクレイピングするPhantomJsとは
- GASでPhantomJSを利用してWebページをスクレイピング
- GASでスクレイピングしたデータからmatchメソッドと正規表現を使って目的の値を取得
- PythonでPhantomJs Cloudを利用してWebページをスクレイピング
- PythonとPhantomJs CloudでスクレイピングしたデータをBeautifulSoupで解析

